Buenos días,
En una integración que estamos haciendo entre dos sistemas recibos un ORU_R01 con los datos de un monitor. Lo recibimos mediante una llamada a nuestro webservice en formato XML.
InterSystems ObjectScript es un lenguaje de programación para operar con datos mediante cualquier modelo de datos que se encuentre en InterSystems Data Platform (Objetos, relacionales, valores clave, documentos, globales) y desarrollar lógica empresarial para aplicaciones del lado del servidor en InterSystems Data Platform.
Buenos días,
En una integración que estamos haciendo entre dos sistemas recibos un ORU_R01 con los datos de un monitor. Lo recibimos mediante una llamada a nuestro webservice en formato XML.
¡Hola, desarrolladores!
En esta serie de artículos hemos hablado del framework iris-datapipe, de cómo nos ayuda a crear "pipes" de datos para la ingesta y procesamiento, y de cómo instalarlo. Vamos a profundizar en cómo implementar uno de esos "pipes" paso a paso.
Si llegaste directamente a este artículo, te recomiendo revisar los anteriores y recordar que iris-datapipe incluye un QuickStart para que puedas explorar sus funcionalidades rápidamente 👌.
El ejemplo que abordaremos está incluido en el QuickStart, por lo que puedes utilizarlo como referencia.
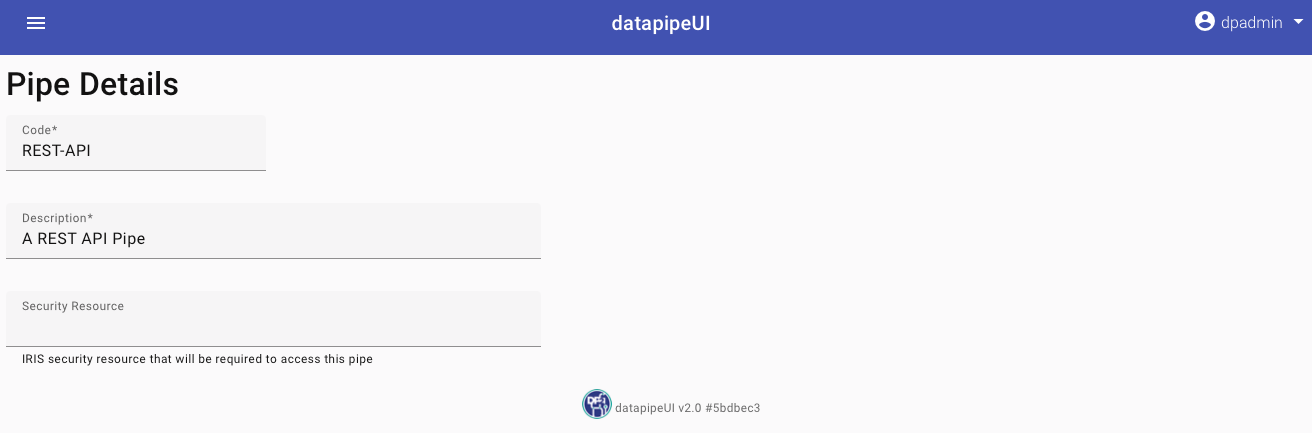
Comienza por definir un nuevo Pipe en la interfaz gráfica. Básicamente, solo se trata de asignar un código y una descripción.
Opcionalmente, puedes especificar un recurso de seguridad de IRIS que se requerirá para poder operar con ese Pipe (esto es útil si necesitas crear pipes que solo sean accesibles a determinados usuarios).
En el ejemplo, definimos un pipe llamado REST-API, que se encargará de procesar datos recibidos desde una API REST, donde llegarán datos sobre personas.
Para procesar los datos utilizando un "pipe", necesitamos seguir los siguientes pasos:
Debemos definir un modelo para los datos que queremos procesar.
Un modelo no es más que una clase que hereda o extiende de DataPipe.Model.cls donde tendrás que implementar algunos métodos.

Tu modelo debe implementar:
En mi ejemplo, el modelo que utilizaré será DataPipe.Test.REST.Models.Person.cls.
Dado que el modelo es una clase convencional en InterSystems IRIS, puedes añadir herencia u otro comportamiento que necesites. En mi caso, heredo de DataPipe.Test.REST.Msg.PersonData, donde tengo definidas las propiedades que me interesa tratar.
El modelo DataPipe.Test.REST.Models.Person.cls tiene diferentes métodos:
Serialize, Deserialize: Se utilizan para indicar cómo serializar/deserializar el modelo. En este caso, utilizo JSON.Normalize: Especifica cómo quiero normalizar el modelo. En mi caso, solo quiero llamar a una transformación de datos./// Normalize model
Method Normalize(Output obj As DataPipe.Model) As %Status
{
set ret = $$$OK
try {
// call normalizaton data transform
set sc = $classmethod("DataPipe.Test.REST.DT.PersonNormalize", "Transform", $this, .obj)
$$$ThrowOnError(sc)
} catch ex {
set ret = ex.AsStatus()
}
quit ret
}
Validate: Indica cómo quiero validar si mi modelo es correcto o no. Puedo añadir "warnings" también. Puedes implementar lo que necesites:/// Validate model
Method Validate(Output errorList As %List) As %Status
{
#define AddError(%list, %code, %desc) set error = ##class(DataPipe.Data.ErrorInfo).%New() set error.Code=%code set error.Desc=%desc do %list.Insert(error)
set ret = $$$OK
try {
set errorList = ##class(%ListOfObjects).%New()
// date of birth
if ..DOB="" {
$$$AddError(errorList, "V001", "DOB required")
} else {
set yearDOB = $extract($zdate(..DOB,8),1,4)
if (yearDOB < 1930) $$$AddError(errorList, "V002", "DOB must be greater than 1930")
if (yearDOB < 1983) $$$AddError(errorList, "W083", "Warning! Older than 1983")
}
// model is invalid if errors (not warnings) found
for i=1:1:errorList.Count() {
set error = errorList.GetAt(i)
set errorCode = error.Code
// in this sample model, all warnings start with "W"
if errorCode'["W" {
$$$ThrowStatus($$$ERROR($$$GeneralError, "Invalid"))
}
}
} catch ex {
set ret = ex.AsStatus()
}
quit ret
}
GetOperation: Indica qué Business Operation quiero que ejecute la operación sobre los datos (lo entenderás mejor cuando comentemos los componentes de interoperabilidad)./// Return the Business Operation name that will run the operation with the model
/// Each Business Operation can be used to hold different queues
Method GetOperation() As %Status
{
quit "Person Operation"
}
RunOperation: Esta es la operación que quiero ejecutar sobre mis datos. Puedo guardarlos en la base de datos o llamar a otro componente de interoperabilidad para continuar el procesamiento más adelante. En mi ejemplo, los guardo en una global y también los envío a otro Business Process./// Run final operation with the model
/// This method can be used to persit data from the model to an operational data store
Method RunOperation(Output errorList As %List, Output log As %Stream.Object, bOperation As Ens.BusinessOperation = "", Output delayedProcessing As %Boolean = 0) As %Status
{
#define AddError(%list, %code, %desc) set error = ##class(DataPipe.Data.ErrorInfo).%New() set error.Code=%code set error.Desc=%desc do %list.Insert(error)
#define AddLog(%log, %msg) do %log.WriteLine("["_$zdt($h,3)_"] "_%msg)
set errorList = ##class(%ListOfObjects).%New()
set log = ##class(%Stream.GlobalCharacter).%New()
set ret = $$$OK
try {
TSTART
$$$AddLog(log, "Transaction Started")
// simulate an operation error
if ##class(Ens.Util.FunctionSet).In(..Name, ##class(DataPipe.Test.HL7.Helper).OperationErrorNames()) {
$$$ThrowStatus($$$ERROR($$$GeneralError, "Simulated Operation Error"))
}
// store serialized model
$$$ThrowOnError(..Serialize(.stream))
set ^zDataPipe($i(^zDataPipe)) = stream.Read()
$$$AddLog(log, "Model Stored in ^zDataPipe("_$get(^zDataPipe)_")")
TCOMMIT
$$$AddLog(log, "Transaction Commited")
// you can send messages to other production components (while you are not on an open transaction)
// you can use this feature to continue processing the record in other component (delayed processing)
set delayedProcessing = 1
if $isobject(bOperation) {
set req = bOperation.OperRequest
$$$ThrowOnError(bOperation.SendRequestAsync("REST Delayed Oper Update", req))
}
} catch ex {
TROLLBACK
$$$AddLog(log, "Rollback!")
set ret = ex.AsStatus()
$$$AddLog(log, "Error catched: "_$system.Status.GetOneStatusText(ret))
// include exception errors into errorList
do $system.Status.DecomposeStatus(ret, .errors)
for i=1:1:errors {
$$$AddError(errorList, "Exception", errors(i))
}
}
quit ret
}
Después de definir tu modelo, necesitas configurar una producción de interoperabilidad usando componentes de DataPipe. iris-datapipe incluye componentes preconstruidos que pueden operar con un modelo DataPipe como el que hemos definido anteriormente.
El único proceso que debes implementar es el proceso de ingestión.

Necesitas crear un nuevo Business Process que utilice como contexto DataPipe.Ingestion.BP.IngestionManagerContext.
Este proceso recibirá la entrada de datos que decidas (en este ejemplo, el mensaje que envía una API REST que actúa como Business Service) y debe implementar:
Identificación de los datos que procesas (InboxAttributes):
Convertir los datos de entrada en el modelo de datos que definiste previamente:

El resto de los componentes de interoperabilidad son proporcionados por iris-datapipe y ya están preconstruidos. Estos componentes llamarán a los distintos métodos implementados en tu modelo.
En general, necesitarás añadir a la producción, por cada "pipe" diferente que quieras implementar:
Aquí tienes la producción de ejemplo que se utiliza en el QuickStart.
Con todo esto, cuando comiencen a llegar datos y se procesen, podrás verlos directamente desde la interfaz gráfica.

¡Espero que os sea útil!
¡Hola a todos de nuevo!
En el artículo anterior hablamos de iris-datapipe, un framework diseñado para ayudarte a definir "pipes" de datos con un patrón de ingesta y procesamiento. Hoy veremos cómo puedes instalarlo y configurarlo paso a paso.
iris-datapipe incluye un QuickStart, que te permite probarlo rápidamente utilizando un contenedor Docker preconfigurado.
Pero, ¿qué debes hacer si quieres usarlo en tu propia instancia?
s r=##class(%Net.HttpRequest).%New(),r.Server="pm.community.intersystems.com",r.SSLConfiguration="ISC.FeatureTracker.SSL.Config" d r.Get("/packages/zpm/latest/installer"),$system.OBJ.LoadStream(r.HttpResponse.Data,"c")
zpm "install iris-datapipe"
iris-datapipe requiere ciertos recursos de seguridad:
DP_ADMIN - Administrador de DataPipe.DP_MENU_DASHBOARD - Acceso al menú "Dashboard" en la interfaz gráfica.DP_MENU_SEARCH - Acceso al menú "Search" en la interfaz gráfica.Necesitarás crear un usuario con acceso a la interfaz gráfica y que utilice estos recursos. A continuación, te muestro un ejemplo de cómo hacerlo:
zn "%SYS"
write ##class(Security.Resources).Create("DP_ADMIN","DataPipe Admin Privilege")
write ##class(Security.Resources).Create("DP_MENU_DASHBOARD","DataPipe UI Dashboard Menu Access")
write ##class(Security.Resources).Create("DP_MENU_SEARCH","DataPipe UI Search Menu Access")
DataPipe_Admin:(¡Importante! Debes otorgarle permisos sobre la base de datos donde hayas instalado iris-datapipe. En este ejemplo, lo hago sobre %DB_USER)
write ##class(Security.Roles).Create("DataPipe_Admin","DataPipe Administrator","DP_ADMIN:RWU,DP_MENU_DASHBOARD:RWU,DP_MENU_SEARCH:RWU,%DB_USER:RW,%DB_IRISSYS:R")
DataPipe_Admin:GRANT INSERT,SELECT,UPDATE ON DataPipe_Data.Pipe, DataPipe_Data.Preference TO DataPipe_Admin
GRANT SELECT ON DataPipe_Data.VInbox, DataPipe_Data.VIngestion, DataPipe_Data.VStaging, DataPipe_Data.VOper TO DataPipe_Admin
dpadmin con la contraseña demo y asignarlo al rol DataPipe_Admin:write ##class(Security.Users).Create("dpadmin","DataPipe_Admin","demo")
Para que la interfaz gráfica funcione correctamente, es importante tener en cuenta la configuración de CORS (Cross-Origin Resource Sharing) y los permisos sobre la base de datos donde tengas instalado DataPipe.
El navegador que utilices para acceder a la interfaz web enviará solicitudes a tu servidor InterSystems IRIS. Como parte de este proceso, el navegador preguntará a IRIS si está permitido realizar estas solicitudes desde su origen (esto es, desde donde estés sirviendo la aplicación web). Puedes encontrar más información en la documentación oficial.
Una manera sencilla de permitir solicitudes desde cualquier origen (incluido localhost) es utilizar directamente esta clase que se usa en el entorno de QuickStart.
Sin embargo, ten en cuenta que siempre debes restringir los posibles orígenes antes de poner un sistema en producción. En el ejemplo proporcionado, necesitarías modificar el método OnHandleCorsRequest.
Es necesario que las solicitudes web que lleguen desde el WebGateway, como CSPSystem, tengan permiso para leer la base de datos donde está instalado iris-datapipe.
En mi ejemplo, una forma sencilla de lograrlo es otorgarle directamente permisos a CSPSystem sobre %DB_USER.
La interfaz gráfica es una aplicación Angular que puedes encontrar aquí: iris-datapipeUI.
Si tienes conocimientos de Angular, no necesitarás mucha explicación. Solo debes saber que puedes hacer un fork/duplicado del repositorio y adaptarlo según tus necesidades.
Si no estás familiarizado con Angular, puedes seguir estos pasos utilizando Docker para simplificar el proceso:
docker compose build
docker compose up -d
Si has seguido los pasos y todo va bien, deberías poder hacer login en la interfaz gráfica con tu usuario dpadmin / demo y verás un entorno vacío:
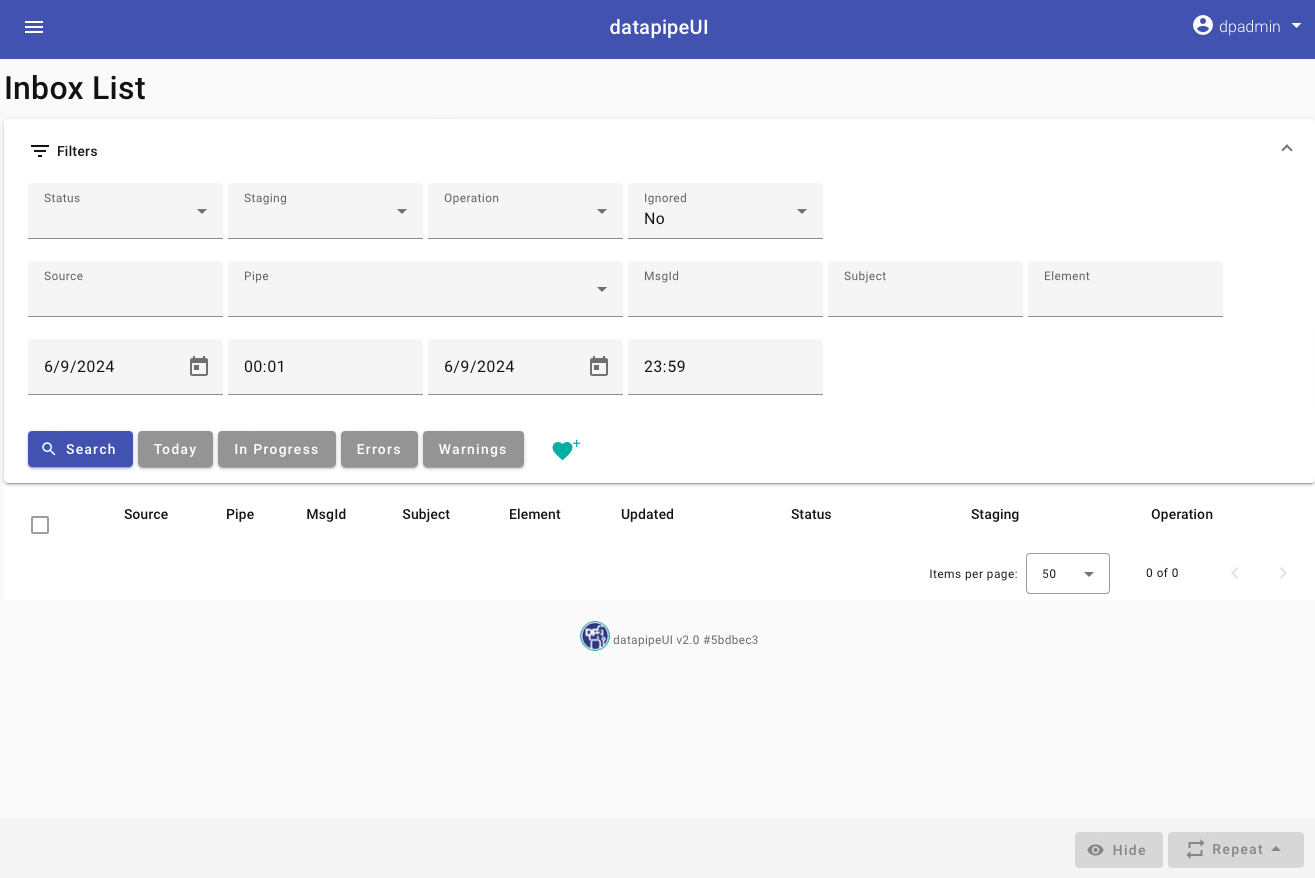
En un próximo artículo hablaremos de cómo crear e implementar "pipes" en iris-datapipe.
Esto se puede lograr utilizando el procedimiento CSV() de la clase %SQL.Util.Procedures . A continuación, podéis ver un ejemplo de uso (suponiendo que el archivo `test.csv` se encuentra en `c:\temp`):
En la sección anterior, exploramos el proceso de instalación y comenzamos a escribir el IRIS en Python nativo. Ahora procederemos a examinar el recorrido global y a interactuar con los objetos de la clase IRIS.
get: esta función se utiliza para obtener valores del nodo de recorrido
deftraversal_firstlevel_subscript():"""
^mygbl(235)="test66,62" and ^mygbl(912)="test118,78"
"""for i in irispy.node('^mygbl'):
print(i, gbl_node.get(i,''))El siguiente código descarga https://www.intersystems.com/assets/intersystems-logo.png y guarda el archivo como c:\temp\test.png.
Es necesario definir una configuración SSL llamada SSLTEST antes de ejecutar este código.
Para los programadores nuevos en ObjectScript, inevitablemente surgirá una pregunta: “¿Cuál es la diferencia entre Methods y ClassMethods?” Una respuesta típica sería: “Un ClassMethod se aplica a una clase, pero un method se aplica a una instancia de esa clase.” Aunque esa respuesta es correcta, carece de información importante sobre cómo estos métodos difieren y cómo se usan en ObjectScript. Muchas cosas podrían escribirse como cualquiera de los dos. Por ejemplo, supongamos que tenemos una clase llamada “User.Person” con una propiedad llamada “Name”. Si quisiéramos crear un método para
¡Hola!
Recientemente he estado investigando una situación molesta mientras editaba clases o rutinas ObjectScript en VSCode.
Lo que me estaba pasando era que, como yo estaba escribiendo en las líneas de código en mi clase (por ejemplo: la adición de un nuevo método; el cambio de la firma de la clase; o de un bloque de código), esto hacía que rápidamente la sintaxis fuera revisada, reformateada y compilada - e inevitablemente, (ya que estaría a la mitad de mi escritura), esto generaba errores de compilación.
Nota: esto fue publicado originalmente el 5 de junio de 2024, pero se presentó como si hubiera sido publicado el 9 de mayo de 2024, por lo que este repost corrige la fecha.
Las actualizaciones recientes del InterSystems Language Server introducen muchas mejoras significativas destinadas a mejorar la experiencia y la productividad del desarrollador. Aquí hablaré de algunas de las más importantes, mientras que la lista completa, que incluye numerosas correcciones de errores, se puede encontrar en el CHANGELOG del Language Server.
Descripciones detalladas para errores de sintaxis
¡Hola a todos!
Llevo muchos años trabajando con Excel y, últimamente, lo he enfocado al tratamiento de bases de datos.
Realmente mi experiencia con Excel ha sido para labores financieras, no tanto analíticas de datos en sí, pero en un proyecto reciente he podido trabajar mucho con SQL y me he interesado un poco por el tema (no soy para nada una experta, ¡aviso!)
Me he preguntado cómo podría unir varios excels en uno para, por ejemplo, entregárselo al Data Análisis utilizando la tecnología InterSystems. He recopilado la información en un pequeño artículo. Espero que sea útil y por supuesto estoy abierta a correcciones.
Vamos a utilizar InterSystems IRIS. Lo que buscaremos es leer los archivos Excel, procesarlos y por último fusionarlos.
Después del último concurso de programación sobre OEX tuve algunas observaciones sorprendentes.
Había aplicaciones casi exclusivas basadas en AI en combinación con módulos Py prefabricados.
Pero profundizando más, todos los ejemplos utilizaron las mismas piezas técnicas de IRIS.
Visto desde el punto de vista de IRIS, era más o menos lo mismo si se buscaba texto
o buscar imágenes u otros patrones.Terminó en métodos casi intercambiables.
.png)
Hola comunidad,
En esta serie de artículos, exploraremos las siguientes opciones de uso de InterSystems SQL:
Hola a todos,
Cuando estamos diseñando un BP que necesita ser reutilizado, a menudo necesitamos desarrollar un componente con un objeto <call> configurable, donde establecemos el destino de la llamada al objeto.
@process.TargetConfigNameSí, se puede lograr.
Aquí está el código completo:
Si tenéis tablas de sistema que implementan la funcionalidad "VERSIONPROPERTY", podéis encontraros con el error 5800. Este artículo explica cómo se produce este error y proporciona soluciones para resolver el problema.
Cuando se implementa la comprobación de versiones, la propiedad especificada por VERSIONPROPERTY se incrementa automáticamente cada vez que se actualiza una instancia de la clase (ya sea mediante objetos o SQL).
Por ejemplo:
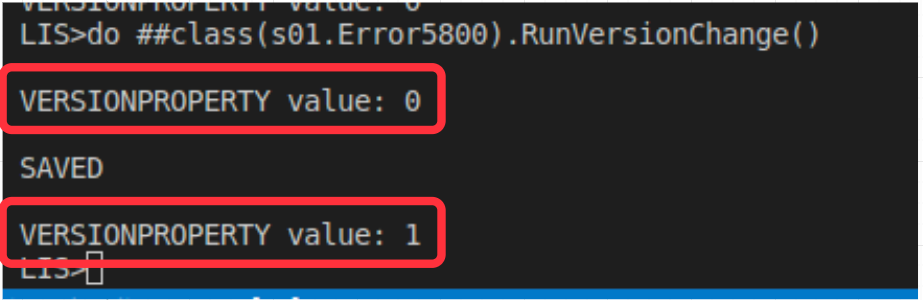
ClassMethod RunVersionChange() As %Status
{
Set sample = ##class(dado.TblSample).%OpenId("42")
Write !,"VERSIONPROPERTY value: "_ sample.VersionCheck
Do sample.StatusSetObjectId("AL")
DO sample.%Save()
WRITE !,!,"SAVED",!
Write !,"VERSIONPROPERTY value: "_ sample.VersionCheck
}
Después de ejecutar el comando %Save(), la propiedad VersionCheck del objeto se incrementó en 1.
Esta característica es útil para realizar evaluaciones y auditorías de registros de bases de datos.
En CACHÉ/IRIS, un mismo objeto que extienda una clase %Persistent puede tener su OREF compartida dentro del mismo proceso.
Por ejemplo:
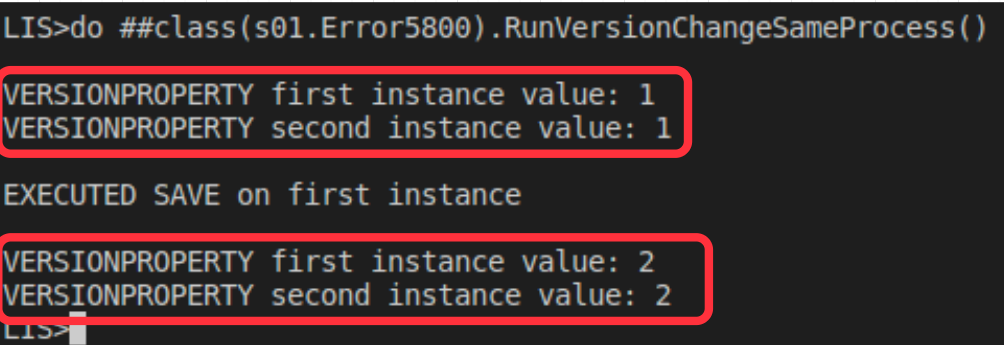
ClassMethod RunVersionChangeSameProcess() As %Status
{
Set firstInstance = ##class(dado.TblSample).%OpenId("42")
Set secondInstance = ##class(dado.TblSample).%OpenId("42")
Write !,"VERSIONPROPERTY first instance value: "_ firstInstance.VersionCheck
Write !,"VERSIONPROPERTY second instance value: "_ secondInstance.VersionCheck
Do firstInstance.StatusSetObjectId("QR")
Do firstInstance.%Save()
WRITE !,!,"EXECUTED SAVE on first instance ",!
Write !,"VERSIONPROPERTY first instance value: "_ firstInstance.VersionCheck
Write !,"VERSIONPROPERTY second instance value: "_ secondInstance.VersionCheck
}
Esto implica que, mientras estén en el mismo proceso, el VersionCheck definido en VERSIONPROPERTY de la tabla dado.TblSample siempre estará actualizado en todas sus instancias.
Sin embargo, cuando se realiza un cambio en diferentes procesos, no ocurre lo mismo, como se demuestra en el ejemplo:
ClassMethod RunVersionChangeTwoProcess() As %Status
{
Set sample = ##class(dado.TblSample).%OpenId("42")
Try {
Do sample.StatusSetObjectId("AL")
$$$THROWONERROR(sc,sample.%Save())
Write !,"VERSIONPROPERTY BEFORE EXECUTING JOB: "_ sample.VersionCheck
JOB ##class(s01.Error5800).RunVersionChange()
hang 2
Do sample.StatusSetObjectId("EP")
Write !,"VERSIONPROPERTY AFTER EXECUTING JOB: "_ sample.VersionCheck
Write !,"TRY RUN SAVE: "
$$$THROWONERROR(sc,sample.%Save())
}
Catch ex {
WRITE !,!,"In the CATCH block"
WRITE !,"Error code=",ex.Code
Do sample.%Reload()
Write !,!,"VERSIONPROPERTY AFTER Reload: "_ sample.VersionCheck
}
}
En este ejemplo, la línea JOB JOB ##class(s01.Error5800).RunVersionChange() se ejecuta después de una instancia de tblSample, sin embargo el proceso 2 realizó un cambio en el mismo registro ya instanciado en JOB 1, finalizándolo antes de tblSample.%Save() en el primer proceso, causando la desincronización de VersionCheck entre procesos.
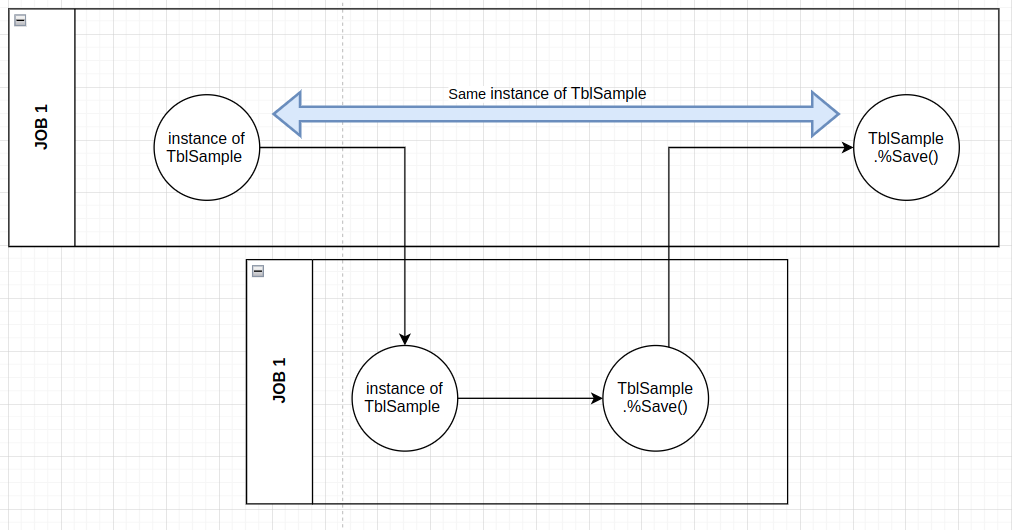
Esto provoca el ERROR 5800:
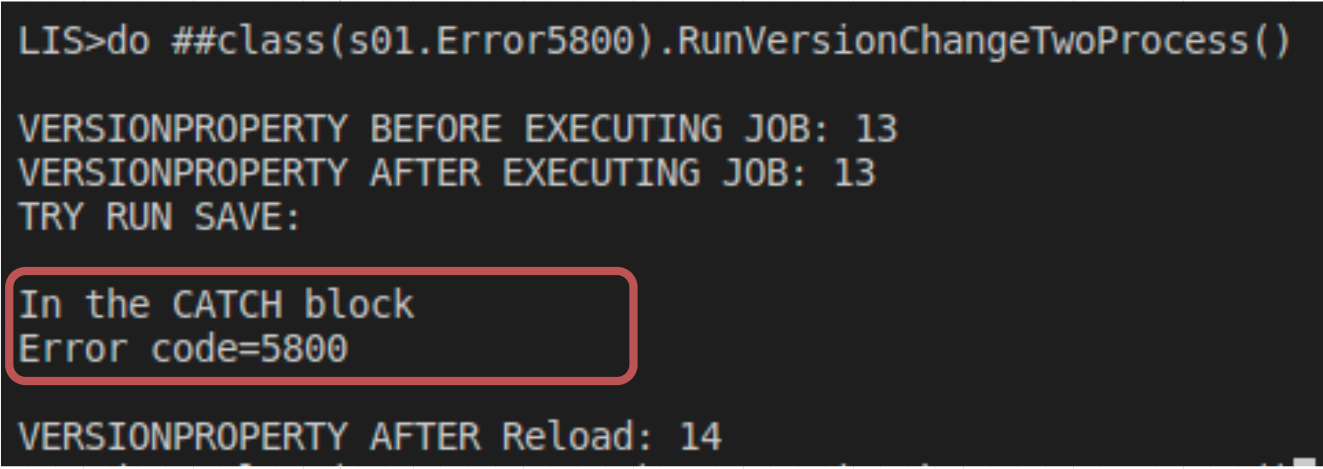
Al consultar el registro en la base de datos, encontramos que el VersionCheck está en una versión más antigua en comparación con el proceso 1:
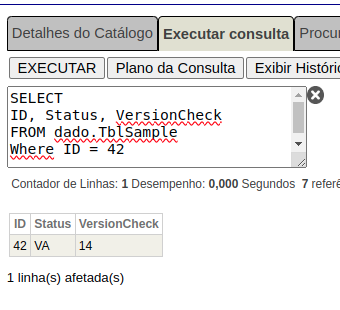
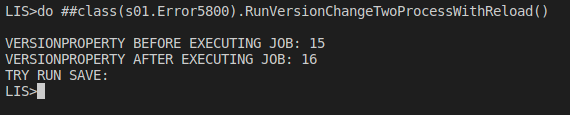
Para evitar el problema, después de las llamadas asíncronas que pueden cambiar el mismo registro de la base de datos, se recomienda utilizar %Reload antes de realizar los cambios necesarios, como en el ejemplo:
ClassMethod RunVersionChangeTwoProcessWithReload() As %Status
{
Set sample = ##class(dado.TblSample).%OpenId("42")
Try {
Do sample.StatusSetObjectId("AL")
$$$THROWONERROR(sc,sample.%Save())
Write !,"VERSIONPROPERTY BEFORE EXECUTING JOB: "_ sample.VersionCheck
JOB ##class(s01.Error5800).RunVersionChange()
hang 2
Do sample.%Reload()
Do sample.StatusSetObjectId("EP")
Write !,"VERSIONPROPERTY AFTER EXECUTING JOB: "_ sample.VersionCheck
Write !,"TRY RUN SAVE: "
$$$THROWONERROR(sc,sample.%Save())
}
Catch ex {
WRITE !,!,"In the CATCH block"
WRITE !,"Error code=",ex.Code
Do sample.%Reload()
Write !,!,"VERSIONPROPERTY AFTER Reload: "_ sample.VersionCheck
}
}
¡Hola, amigos!
A menudo, cuando desarrollamos soluciones comerciales, existe la necesidad de desplegar soluciones sin código fuente, por ejemplo, para preservar la propiedad intelectual.
Una de las formas de conseguirlo es utilizar InterSystems Package Manager.
Aquí he pedido a Midjourney que pinte una propiedad intelectual de software:

¿Cómo se puede lograr esto con IPM?
De hecho, es muy sencillo; basta con añadir la cláusula Deploy="true" en el elemento Resource del manifiesto module.xml. Ver Documentación.
He decidido pasaros el ejemplo más simple posible para ilustrar cómo funciona y también para daros una plantilla de entorno de desarrollo que os permita empezar a construir y desplegar vuestros propios módulos sin código fuente. ¡Allá vamos!
Hola a todos,
Por un requerimiento del cliente, tenermos un BS Rest Api con un montón de métodos, necesitamos obtener la IP del invocador, el método y cual es el tiempo que la API ha tomado para procesar.
He encontrado el evento onPreDispatch donde puedo capturar la IP, ClassMethod, etc.. Estoy usando una variable global para guardar esta información.
Quería compartiros hoy un pequeño truco para personalizar cómo se muestran los mensajes en el Visor de Mensajes. En concreto, cómo mostrar mensajes JSON directamente en el Visor de Mensajes en lugar de serializados como XML.
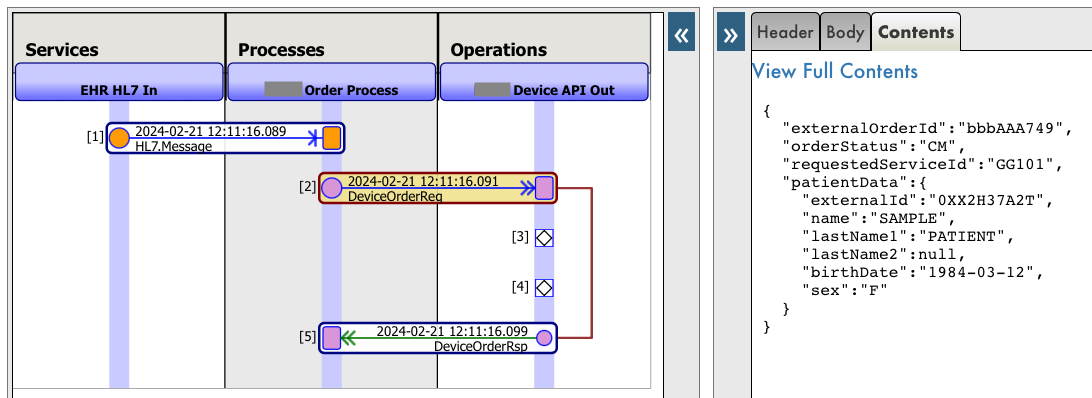
Los mensajes son los objetos que utilizamos para comunicar componentes de una producción de interoperabilidad. En mi caso me había definido un mensaje que utilizaba después para pasar a JSON y enviar a una API. Este mensaje está definido como un mensaje convencional y también como %JSON.Adaptor para poder exportar / importar directamente a JSON.
Class interop.msg.DeviceOrderReq Extends (Ens.Request, %JSON.Adaptor)
{
Parameter %JSONNULL As BOOLEAN = 1;
Property externalOrderId As %String(MAXLEN = "");
Property orderStatus As %String;
Property requestedServiceId As %String(MAXLEN = "");
Property patientData As interop.msg.elements.PatientData;
}
El mensaje funciona correctamente cuando hago diferentes pruebas en mi producción, sin embargo en el Visor de Mensajes aparece con la representación por defecto XML:

La representación es correcta, pero me sería mucho más intuitivo ver el mensaje representado directamente en JSON. Para ello, podemos sobreescribir el método %ShowContents en nuestro mensaje.
En mi caso, para poder reutilizar código me he creado una clase llamada JSONMessage. Esta clase sobreescribe el %ShowContents para mostrar la representación en JSON formateada del objeto.
Class interop.msg.JSONMessage Extends (Ens.Request, %JSON.Adaptor)
{
/// This method is called by the Management Portal to determine the content type that will be returned by the <method>%ShowContents</method> method.
/// The return value is a string containing an HTTP content type.
Method %GetContentType() As %String
{
Quit "text/html"
}
/// This method is called by the Management Portal to display a message-specific content viewer.<br>
/// This method displays its content by writing out to the current device.
/// The content should match the type returned by the <method>%GetContentType</method> method.<br>
Method %ShowContents(pZenOutput As %Boolean = 0)
{
do ..%JSONExportToString(.jsonExport)
set formatter = ##class(%JSON.Formatter).%New()
do formatter.FormatToString(jsonExport, .json)
&html<<pre>#(json)#</pre>>
}
}
Por último, sólo queda cambiar la definición del mensaje original para que herede de JSONMessage:
Class interop.msg.DeviceOrderReq Extends (JSONMessage, Ens.Request)
{
Parameter %JSONNULL As BOOLEAN = 1;
Property externalOrderId As %String(MAXLEN = "");
Property orderStatus As %String;
Property requestedServiceId As %String(MAXLEN = "");
Property patientData As interop.msg.elements.PatientData;
}
Hace poco me di cuenta de que llevaba mucho tiempo sin comentaros las últimas novedades de la extensión de ObjectScript para Visual Studio Code.
Me complace anunciar la versión 2.12.1 de la extensión de ObjectScript, que contiene un buen número de mejoras para hacer la vida más fácil a los desarrolladores. Describo más abajo las más destacadas, incluyendo la petición nº 1 del Global Summit -- ¡Importación de XML!
Como siempre, podéis encontrar la lista completa de modificaciones en el CHANGELOG, incluyendo muchas correcciones de errores y vulnerabilidades.
Interactuar con usuarios en la terminal: una guía para usar %Library.Prompt en IRIS

¿Alguna vez te has preguntado cómo comandos como ^DATABASE atraen a los usuarios en la terminal? O tal vez esté escribiendo una rutina de automatización y desee formas de especificar opciones directamente desde la terminal. Afortunadamente, la clase %Library.Prompt en IRIS ofrece una forma sencilla de hacerlo.
Para entradas básicas, como pedirle al usuario que proporcione una ruta de archivo o un espacio de nombres, utilice el siguiente código:
Hola comunidad,
Si, ya sé que hay otra pregunta con el mismo problema "VS Code - debugging doesn't work", pero mi instancia de IRIS no está usando IIS.
Hace tiempo, podía depurar sin problemas, pero después de algunas actualizaciones de Visual Studio, tengo el siguiente error
Failed to start the debug session. Check that the Intersystems server's web server supports WebSockets
He activado el protocolo WebSocket en el servidor (Windows Server 2019) pero sigue sin funcionar.
La instancia de IRIS no está usando IIS, creo que está usando el Apache por defecto.
¿Necesito hacer algo en especial?
Tenemos un conjunto de datos bastante apetecible con recetas escritas por múltiples usuarios de Reddit, sin embargo, la mayor parte de la información está en texto libre en forma de título y descripción de un mensaje. Vamos a averiguar cómo podemos, de forma muy sencilla, cargar los datos, extraer algunas características y analizarlos empleando funcionalidades de LLM (Large Language Model) de OpenAI desde Python Embebido y el framework Langchain.
Lo primero es lo primero: ¿necesitamos cargar los datos o podemos sencillamente conectarnos a ellos?
Hay diferentes formas para plantearlo: por ejemplo, con el Mapeo de registros CSV que puedes utilizar en una producción de interoperabilidad o incluso instalar directamente una aplicación de OpenExchange como csvgen para que nos ayude.
Utilizaremos en este caso las Foreign Tables. Una funcionalidad muy útil para proyectar datos físicamente almacenados en otra parte y tenerlos accesibles desde el SQL de IRIS. Podemos utilizarlo directamente para echar un primer vistazo a los ficheros del conjunto de datos.
Creamos un Foreign Server:
CREATE FOREIGN SERVER dataset FOREIGN DATA WRAPPER CSV HOST '/app/data/'
Y a continuación, creamos una Foreign Table que se conecta al fichero CSV:
CREATE FOREIGN TABLE dataset.Recipes (
CREATEDDATE DATE,
NUMCOMMENTS INTEGER,
TITLE VARCHAR,
USERNAME VARCHAR,
COMMENT VARCHAR,
NUMCHAR INTEGER
) SERVER dataset FILE 'Recipes.csv' USING
{
"from": {
"file": {
"skip": 1
}
}
}
¡Y ya está!, inmediatamente podemos lanzar consultas SQL sobre dataset.Recipes:

## ¿Qué datos necesitamos? Los datos son muy interesantes y tenemos hambre. Sin embargo, si queremos decidir qué receta vamos a cocinar necesitamos algo más de información que podamos utilizar para analizar las recetas.
Vamos a trabajar con dos clases persistentes (tablas):
Podemos ahora cargar en nuestras tablas yummy.data* el contenido del conjunto de datos de recetas:
do ##class(yummy.Utils).LoadDataset()
Hasta aquí tiene buena pinta, pero aún debemos averiguar cómo vamos a generar los datos para los campos como: Score, Difficulty, Ingredients, PreparationTime and CuisineType.
## Analizar las recetas Queremos procesar el título y la descripción de cada receta y:
Vamos a utilizar lo siguiente:
Los LLM (Large Language Models) son una herramienta realmente increíble para procesar lenguaje natural.
LangChain está preparado para trabajar con Python, así que podemos utilizarlo directamente en InterSystems IRIS a través de Embedded Python.
La clase SimpleOpenAI tiene esta pinta:
/// Simple OpenAI analysis for recipes
Class yummy.analysis.SimpleOpenAI Extends Analysis
{
Property CuisineType As %String;
Property PreparationTime As %Integer;
Property Difficulty As %String;
Property Ingredients As %String;
/// Run
/// You can try this from a terminal:
/// set a = ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(8))
/// do a.Run()
/// zwrite a
Method Run()
{
try {
do ..RunPythonAnalysis()
set reasons = ""
// mis estilos de cocina favoritos
if "spanish,french,portuguese,italian,korean,japanese"[..CuisineType {
set ..Score = ..Score + 2
set reasons = reasons_$lb("It seems to be a "_..CuisineType_" recipe!")
}
// no quiero estar el día entero cocinando :)
if (+..PreparationTime < 120) {
set ..Score = ..Score + 1
set reasons = reasons_$lb("You don't need too much time to prepare it")
}
// bonus para mis ingredientes favoritos!
set favIngredients = $listbuild("kimchi", "truffle", "squid")
for i=1:1:$listlength(favIngredients) {
set favIngred = $listget(favIngredients, i)
if ..Ingredients[favIngred {
set ..Score = ..Score + 1
set reasons = reasons_$lb("Favourite ingredient found: "_favIngred)
}
}
set ..Reason = $listtostring(reasons, ". ")
} catch ex {
throw ex
}
}
/// Update recipe with analysis results
Method UpdateRecipe()
{
try {
// call parent class implementation first
do ##super()
// add specific OpenAI analysis results
set ..Recipe.Ingredients = ..Ingredients
set ..Recipe.PreparationTime = ..PreparationTime
set ..Recipe.Difficulty = ..Difficulty
set ..Recipe.CuisineType = ..CuisineType
} catch ex {
throw ex
}
}
/// Run analysis using embedded Python + Langchain
/// do ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(8)).RunPythonAnalysis(1)
Method RunPythonAnalysis(debug As %Boolean = 0) [ Language = python ]
{
# load OpenAI APIKEY from env
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv('/app/.env')
# account for deprecation of LLM model
import datetime
current_date = datetime.datetime.now().date()
# date after which the model should be set to "gpt-3.5-turbo"
target_date = datetime.date(2024, 6, 12)
# set the model depending on the current date
if current_date > target_date:
llm_model = "gpt-3.5-turbo"
else:
llm_model = "gpt-3.5-turbo-0301"
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
# init llm model
llm = ChatOpenAI(temperature=0.0, model=llm_model)
# prepare the responses we need
cuisine_type_schema = ResponseSchema(
name="cuisine_type",
description="What is the cuisine type for the recipe? \
Answer in 1 word max in lowercase"
)
preparation_time_schema = ResponseSchema(
name="preparation_time",
description="How much time in minutes do I need to prepare the recipe?\
Anwer with an integer number, or null if unknown",
type="integer",
)
difficulty_schema = ResponseSchema(
name="difficulty",
description="How difficult is this recipe?\
Answer with one of these values: easy, normal, hard, very-hard"
)
ingredients_schema = ResponseSchema(
name="ingredients",
description="Give me a comma separated list of ingredients in lowercase or empty if unknown"
)
response_schemas = [cuisine_type_schema, preparation_time_schema, difficulty_schema, ingredients_schema]
# get format instructions from responses
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
analysis_template = """\
Interprete and evaluate a recipe which title is: {title}
and the description is: {description}
{format_instructions}
"""
prompt = ChatPromptTemplate.from_template(template=analysis_template)
messages = prompt.format_messages(title=self.Recipe.Title, description=self.Recipe.Description, format_instructions=format_instructions)
response = llm(messages)
if debug:
print("======ACTUAL PROMPT")
print(messages[0].content)
print("======RESPONSE")
print(response.content)
# populate analysis with results
output_dict = output_parser.parse(response.content)
self.CuisineType = output_dict['cuisine_type']
self.Difficulty = output_dict['difficulty']
self.Ingredients = output_dict['ingredients']
if type(output_dict['preparation_time']) == int:
self.PreparationTime = output_dict['preparation_time']
return 1
}
}
El método RunPythonAnalysis es donde sucede todo lo relativo a OpenAI :). Puedes probarlo directamente desde tu terminal utilizando una receta en particular:
do ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(12)).RunPythonAnalysis(1)
Obtendremos un resultado como el siguiente:
USER>do ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(12)).RunPythonAnalysis(1)
======ACTUAL PROMPT
Interprete and evaluate a recipe which title is: Folded Sushi - Alaska Roll
and the description is: Craving for some sushi but don't have a sushi roller? Try this easy version instead. It's super easy yet equally delicious!
[Video Recipe](https://www.youtube.com/watch?v=1LJPS1lOHSM)
# Ingredients
Serving Size: \~5 sandwiches
* 1 cup of sushi rice
* 3/4 cups + 2 1/2 tbsp of water
* A small piece of konbu (kelp)
* 2 tbsp of rice vinegar
* 1 tbsp of sugar
* 1 tsp of salt
* 2 avocado
* 6 imitation crab sticks
* 2 tbsp of Japanese mayo
* 1/2 lb of salmon
# Recipe
* Place 1 cup of sushi rice into a mixing bowl and wash the rice at least 2 times or until the water becomes clear. Then transfer the rice into the rice cooker and add a small piece of kelp along with 3/4 cups plus 2 1/2 tbsp of water. Cook according to your rice cookers instruction.
* Combine 2 tbsp rice vinegar, 1 tbsp sugar, and 1 tsp salt in a medium bowl. Mix until everything is well combined.
* After the rice is cooked, remove the kelp and immediately scoop all the rice into the medium bowl with the vinegar and mix it well using the rice spatula. Make sure to use the cut motion to mix the rice to avoid mashing them. After thats done, cover it with a kitchen towel and let it cool down to room temperature.
* Cut the top of 1 avocado, then slice into the center of the avocado and rotate it along your knife. Then take each half of the avocado and twist. Afterward, take the side with the pit and carefully chop into the pit and twist to remove it. Then, using your hand, remove the peel. Repeat these steps with the other avocado. Dont forget to clean up your work station to give yourself more space. Then, place each half of the avocado facing down and thinly slice them. Once theyre sliced, slowly spread them out. Once thats done, set it aside.
* Remove the wrapper from each crab stick. Then, using your hand, peel the crab sticks vertically to get strings of crab sticks. Once all the crab sticks are peeled, rotate them sideways and chop them into small pieces, then place them in a bowl along with 2 tbsp of Japanese mayo and mix until everything is well mixed.
* Place a sharp knife at an angle and thinly slice against the grain. The thickness of the cut depends on your preference. Just make sure that all the pieces are similar in thickness.
* Grab a piece of seaweed wrap. Using a kitchen scissor, start cutting at the halfway point of seaweed wrap and cut until youre a little bit past the center of the piece. Rotate the piece vertically and start building. Dip your hand in some water to help with the sushi rice. Take a handful of sushi rice and spread it around the upper left hand quadrant of the seaweed wrap. Then carefully place a couple slices of salmon on the top right quadrant. Then place a couple slices of avocado on the bottom right quadrant. And finish it off with a couple of tsp of crab salad on the bottom left quadrant. Then, fold the top right quadrant into the bottom right quadrant, then continue by folding it into the bottom left quadrant. Well finish off the folding by folding the top left quadrant onto the rest of the sandwich. Afterward, place a piece of plastic wrap on top, cut it half, add a couple pieces of ginger and wasabi, and there you have it.
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "```json" and "```":
json
{
"cuisine_type": string // What is the cuisine type for the recipe? Answer in 1 word max in lowercase
"preparation_time": integer // How much time in minutes do I need to prepare the recipe? Anwer with an integer number, or null if unknown
"difficulty": string // How difficult is this recipe? Answer with one of these values: easy, normal, hard, very-hard
"ingredients": string // Give me a comma separated list of ingredients in lowercase or empty if unknown
}
======RESPONSE
json
{
"cuisine_type": "japanese",
"preparation_time": 30,
"difficulty": "easy",
"ingredients": "sushi rice, water, konbu, rice vinegar, sugar, salt, avocado, imitation crab sticks, japanese mayo, salmon"
}
Tiene muy buena pinta. Parece que nuestro prompt o pregunta a OpenAI es capaz de devolvernos información que realmente podemos utilizar. Vamos a ejecutar el análisis completo desde el terminal:
set a = ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(12))
do a.Run()
zwrite a
USER>zwrite a
a=37@yummy.analysis.SimpleOpenAI ; <OREF>
+----------------- general information ---------------
| oref value: 37
| class name: yummy.analysis.SimpleOpenAI
| reference count: 2
+----------------- attribute values ------------------
| CuisineType = "japanese"
| Difficulty = "easy"
| Ingredients = "sushi rice, water, konbu, rice vinegar, sugar, salt, avocado, imitation crab sticks, japanese mayo, salmon"
| PreparationTime = 30
| Reason = "It seems to be a japanese recipe!. You don't need too much time to prepare it"
| Score = 3
+----------------- swizzled references ---------------
| i%Recipe = ""
| r%Recipe = "30@yummy.data.Recipe"
+-----------------------------------------------------
## Analizar todas las recetas Naturalmente, querremos ejecutar el análisis para todas las recetas que hemos cargado.
Puedes analizar un rango de recetas (utilizando sus identificadores), de esta forma:
USER>do ##class(yummy.Utils).AnalyzeRange(1,10)
> Recipe 1 (1.755185s)
> Recipe 2 (2.559526s)
> Recipe 3 (1.556895s)
> Recipe 4 (1.720246s)
> Recipe 5 (1.689123s)
> Recipe 6 (2.404745s)
> Recipe 7 (1.538208s)
> Recipe 8 (1.33001s)
> Recipe 9 (1.49972s)
> Recipe 10 (1.425612s)
Después de eso, vamos a echar un vistazo de nuevo a la tabla de recetas y comprobemos los resultados:
select * from yummy_data.Recipe

Creo que podría intentar la Pizza con calabaza o el Tofu con Kimchi y cerdo al estilo coreano :). De todas formas, debo asegurarme y preguntar en casa antes de empezar a cocinar :)
Puedes encontrar el ejemplo completo en https://github.com/isc-afuentes/recipe-inspector
Con este ejemplo sencillo hemos aprendido cómo utilizar técnicas LLM para extraer características y analizar ciertas partes de nuestros datos en InterSystems IRIS.
Con esto como punto de partida, podrías plantearte cosas como:
¿Qué otras cosas se os ocurren?
La invención y popularización de LLMs (Large Language Models) como GPT-4 de OpenAI ha desencadenado una ola de soluciones innovadoras que permiten aprovechar grandes volúmenes de datos no estructurados, que eran prácticamente imposibles de procesar manualmente hasta hace poco. Estas aplicaciones pueden incluir la recuperación de datos (echad un vistazo al curso sobre ML301 de Don Woodlock, con una excelente introducción a la Generación Aumentada de Recuperación), el análisis de sentimientos, e incluso agentes de IA totalmente autónomos, por nombrar sólo algunos ejemplos!
En este artículo, quiero demostrar cómo la funcionalidad de Python Embebido de IRIS puede ser utilizada para interactuar directamente con la librería Python de OpenAI, a través de la creación de una sencilla aplicación de etiquetado de datos que asignará automáticamente palabras clave a los registros que metamos en una tabla de IRIS. Estas palabras clave pueden después ser usadas para buscar y categorizar los datos, así como para analítica de datos. Utilizaré reseñas de productos realizadas por clientes como ejemplo de caso de uso.
¡Hola Comunidad!
¡Muchísimas gracias a todos los que habéis participado en el concurso Advent of Code 2023!
Y nuestra enhorabuena a los ganadores:
🥈 @Maksym Shcherban (w/ repo)
🥉 @Yuval Golan (w/ repo)
Aquí podéis ver la clasificación final (leaderboard):
Cuando ejecutéis comandos del SO, utilizad el comando $ZF(-100).
do$ZF(-100,"",program,args) // Execute the Windows command [synchronously].do$ZF(-100,"/ASYNC",program,args) // Executes a Windows command [asynchronously].Cuando ejecutéis comandos de la shell del SO, como mkdir o copy, hemos de especificar /SHELL.
do$zf(-100,"/shell /async","mkdir","c:\temp\x")¡Bienvenidos a todos!
En este breve artículo quería presentar un ejemplo de uso que seguramente a muchos de los que trabajéis con IRIS como backend de vuestras aplicaciones web os hayáis encontrado en más de una ocasión y sería el de la necesidad de enviar desde el frontend un archivo a vuestro servidor.
Esta app evita añadir %JSONAdaptor a cada clase. En su lugar usa las funciones SQL JSON_OBJECT() para crear mis objetos JSON. Con este enfoque, se puede añadir JSON a cualquier clase - incluso a las implementadas - sin ninguna necesidad de cambiar o recompilar.
La idea inicial surge a raíz de implementar la exportación de relaciones M:N como objetos o matrices JSON.
La típica estructura de la exportación es
{ M-element : {M-object},
related-N-elements:
[
{N-element},
{N-element},
{N-element}
]
}
Los datos para la demo son un fragmento de los Miembros de la Comunidad de Desarrolladores y sus Insignias conseguidas en GlobalMasters. Los nombres reales están modificados.
¡Hola desarrolladores!
Si os gustan los famosos Concursos de Adviento "Advent of Code", con sus retos de programación diarios hasta el día de Navidad, os encantará nuestra versión, que vuelve un año más (algunos ya estaban preguntando por ella 😁).
➡️ Participad en el Advent of Code 2023 de InterSystems y podréis ganar alguno de los premios en metálico que hay para los ganadores. ¡Animaos a poner a prueba vuestros conocimientos de ObjectScript!
.jpg)
Me gustaría adelantaros una mejora sobre cómo generamos e invocamos el código de los métodos en IRIS 2023.1.
Una clase en IRIS se compone de dos componentes de runtime principales:
La información sobre las propiedades definidas en una clase se puede obtener usando las siguientes clases del sistema:
%Dictionary.PropertyDefinition
El ejemplo de descripción del código es el siguiente.
Una herramienta (utilidad ^GLOBUFF) está disponible para verificar el uso de la memoria caché de la base de datos para cada global.
La utilidad se puede ejecutar directamente o mediante programación en el namespace %SYS .
Así se ejecutaría directamente:
{kind=link}