¡Buenas a todos!
Vamos a cerrar el año por todo lo alto. Os invitamos a este webinar en español con @Pierre-Yves Duquesnoy "Smart Supply Chain 360: Ver, Decidir, Actuar" el jueves 27 de noviembre, a las 4:00 PM (CET).

Esta etiqueta se relaciona con las discusiones sobre el desarrollo de soluciones analíticas y de inteligencia empresarial, visualización, Indicadores clave del rendimiento (KPI) y otros tipos de administradores sobre los indicadores empresariales.
¡Buenas a todos!
Vamos a cerrar el año por todo lo alto. Os invitamos a este webinar en español con @Pierre-Yves Duquesnoy "Smart Supply Chain 360: Ver, Decidir, Actuar" el jueves 27 de noviembre, a las 4:00 PM (CET).
Quizá esto sea bien conocido, pero quería ayudar a compartirlo.
Considerad que tenéis las siguientes definiciones de clases persistentes:
Una clase Factura con una propiedad que referencia a Proveedor.
InterSystems ha estado a la vanguardia de la tecnología de bases de datos desde su creación, siendo pionera en innovaciones que superan constantemente a competidores como Oracle, IBM y Microsoft. Al centrarse en un diseño eficiente del núcleo y adoptar un enfoque sin concesiones en el rendimiento de los datos, InterSystems se ha hecho un hueco en las aplicaciones de misión crítica, garantizando fiabilidad, velocidad y escalabilidad.
Una historia de excelencia técnica
Nos han desbordado las previsiones. Así que, ante el éxito de asistencia y todos los comentarios recibidos, os anuncio una nueva convocatoria extraordinaria del curso: Desarrollo de asistentes virtuales con RAG. ¡Mantenemos el precio promocional reducido! (plazas limitadas).
¿Preferís no leer? Echad un vistazo al vídeo demo:
El auge de los proyectos de Big Data, las analíticas en tiempo real con herramientas self-service, los servicios de consultas en línea y las redes sociales, entre otros, han habilitado escenarios para consultas masivas y de alto rendimiento. En respuesta a este desafío, se creó la tecnología MPP (procesamiento masivamente paralelo) y rápidamente se consolidó. Entre las opciones de MPP de código abierto, Presto (https://prestodb.io/) es la más conocida. Surgió en Facebook y se utilizó para análisis de datos, pero luego se convirtió en código abierto. Sin embargo, desde que Teradata se unió a la
Hola Comunidad,
En este artículo, os presentaré mi aplicación iris-DataViz.
Nos alegra compartir que el equipo de Servicios de Aprendizaje ha añadido recientemente nuevos contenidos a nuestra Ruta de Aprendizaje de InterSystems Reports. Estos últimos vídeos, creados por nuestro socio, insightsoftware, proporcionan instrucciones para desarrollar informes con InterSystems Report Designer.
En estos tres breves vídeos, aprenderéis a:
La invención y popularización de LLMs (Large Language Models) como GPT-4 de OpenAI ha desencadenado una ola de soluciones innovadoras que permiten aprovechar grandes volúmenes de datos no estructurados, que eran prácticamente imposibles de procesar manualmente hasta hace poco. Estas aplicaciones pueden incluir la recuperación de datos (echad un vistazo al curso sobre ML301 de Don Woodlock, con una excelente introducción a la Generación Aumentada de Recuperación), el análisis de sentimientos, e incluso agentes de IA totalmente autónomos, por nombrar sólo algunos ejemplos!
En este artículo, quiero demostrar cómo la funcionalidad de Python Embebido de IRIS puede ser utilizada para interactuar directamente con la librería Python de OpenAI, a través de la creación de una sencilla aplicación de etiquetado de datos que asignará automáticamente palabras clave a los registros que metamos en una tabla de IRIS. Estas palabras clave pueden después ser usadas para buscar y categorizar los datos, así como para analítica de datos. Utilizaré reseñas de productos realizadas por clientes como ejemplo de caso de uso.
 | Cómo incluir IRIS Data en vuestro almacén de datos de Google Big Query y en vuestras exploraciones de datos de Data Studio. En este artículo utilizaremos Google Cloud Dataflow para conectarnos a nuestro Servicio de InterSystems Cloud SQL y crear un trabajo para persistir los resultados de una consulta de IRIS en Big Query en un intervalo. Si tuvisteis la suerte de obtener acceso a Cloud SQL en el Global Summit 2022, como se menciona en "InterSystems IRIS: What's New, What's Next" (InterSystems IRIS: Lo nuevo, lo siguiente), el ejemplo será pan comido, pero se puede realizar con cualquier punto de acceso público o vpc que hayáis provisionado. |


jdbc:IRIS://k8s-c5ce7068-a4244044-265532e16d-2be47d3d6962f6cc.elb.us-east-1.amazonaws.com:1972/USERSQLAdmin/Testing12!com.intersystems.jdbc.IRISDrivergcloud projects create iris-2-datastudio --set-as-default
gcloud services enable bigquery.googleapis.com gcloud services enable dataflow.googleapis.com gcloud services enable storage.googleapis.com
gsutil mb gs://iris-2-datastudio
wget https://github.com/intersystems-community/iris-driver-distribution/raw/main/intersystems-jdbc-3.3.0.jar gsutil cp intersystems-jdbc-3.3.0.jar gs://iris-2-datastudio
bq --location=us mk \ --dataset \ --description "sqlaas to big query" \ iris-2-datastudio:irisdata
Aquí es donde una ventaja súper potente se convierte en algo molesto para nosotros. Big Query puede crear tablas en tiempo real si se le suministra un esquema junto con una carga útil. Esto es genial dentro de pipelines y soluciones pero, en nuestro caso, necesitamos establecer la tabla con antelación. El proceso es sencillo, ya que se puede exportar un archivo CSV desde la base de datos IRIS con bastante facilidad con herramientas como DBeaver etc. y, cuando se tenga, se puede invocar el diálogo "Create table" (crear tabla) debajo del conjunto de datos que se creó y utilizar el archivo CSV para crear la tabla. Hay que asegurarse de tener marcada la opción "auto generate schema" ("autogenerar esquema") en la parte inferior del cuadro de diálogo. 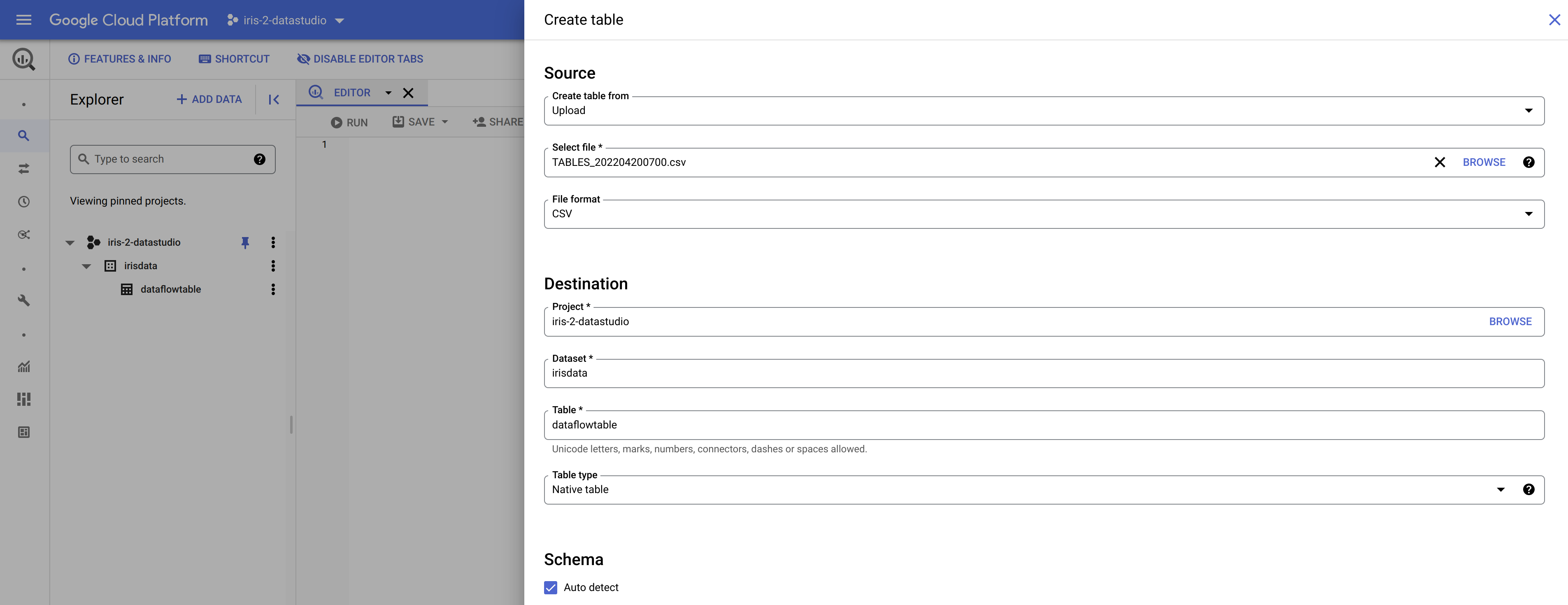 Esto debería completar la configuración de Google Cloud, y deberíamos estar listos para configurar y ejecutar nuestro trabajo Dataflow.
Esto debería completar la configuración de Google Cloud, y deberíamos estar listos para configurar y ejecutar nuestro trabajo Dataflow.
Si seguisteis los pasos anteriores, deberíais tener lo siguiente en vuestro inventario para ejecutar el trabajo para leer vuestros datos de InterSystems IRIS e ingerirlos en Google Big Query utilizando Google Dataflow.
En Google Cloud Console, id a Dataflow y seleccionad "Create Job from Template" (Crear trabajo a partir de plantilla)

Esta es una imagen bastante innecesaria sobre cómo rellenar un formulario con los requisitos previos generados, pero destaca la fuente de los componentes...!
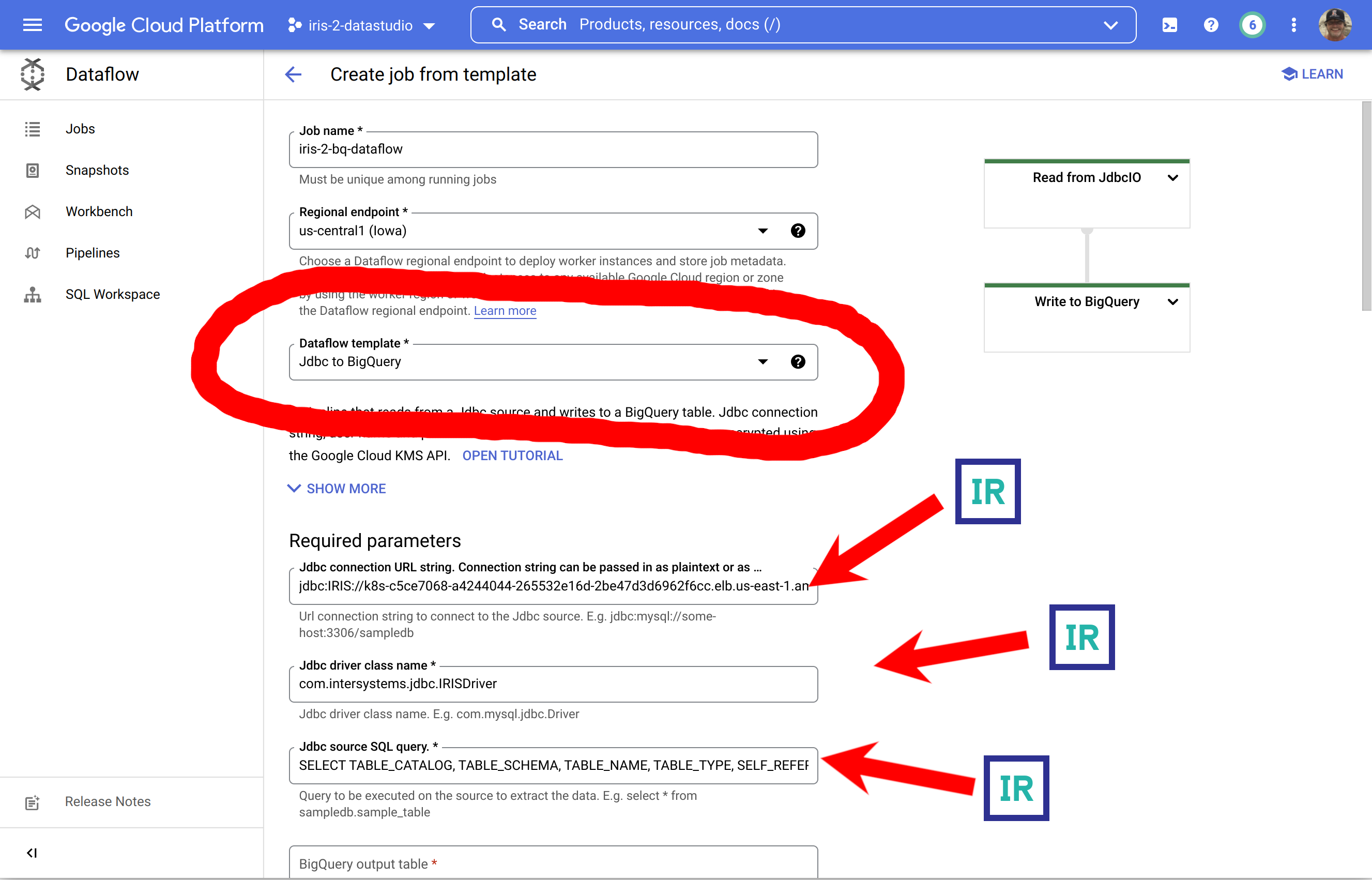
... para completarlo, aseguraos de expandir la sección inferior y facilitar vuestras credenciales para IRIS.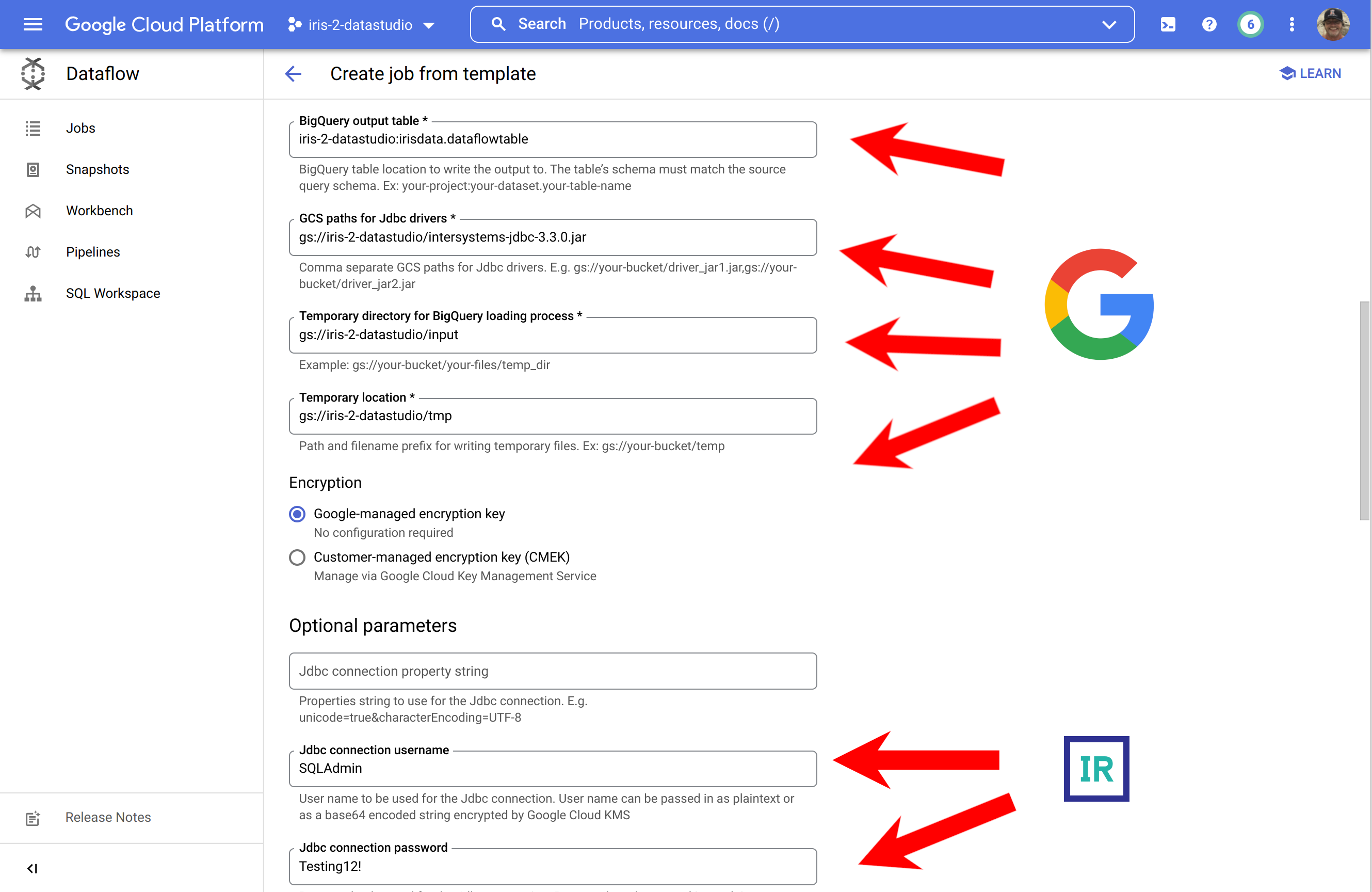
Para los que encontrasteis esas capturas de pantalla ofensivas a vuestra inteligencia, esta es la ruta alternativa a seguir para manteneros en vuestra zona de confort en la CLI para ejecutar el trabajo:
gcloud dataflow jobs run iris-2-bq-dataflow \ --gcs-location gs://dataflow-templates-us-central1/latest/Jdbc_to_BigQuery \ --region us-central1 --num-workers 2 \ --staging-location gs://iris-2-datastudio/tmp \ --parameters connectionURL=jdbc:IRIS://k8s-c5ce7068-a4244044-265532e16d-2be47d3d6962f6cc.elb.us-east-1.amazonaws.com:1972/USER,driverClassName=com.intersystems.jdbc.IRISDriver,query=SELECT TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME, TABLE_TYPE, SELF_REFERENCING_COLUMN_NAME, REFERENCE_GENERATION, USER_DEFINED_TYPE_CATALOG, USER_DEFINED_TYPE_SCHEMA, USER_DEFINED_TYPE_NAME, IS_INSERTABLE_INTO, IS_TYPED, CLASSNAME, DESCRIPTION, OWNER, IS_SHARDED FROM INFORMATION_SCHEMA.TABLES;,outputTable=iris-2-datastudio:irisdata.dataflowtable,driverJars=gs://iris-2-datastudio/intersystems-jdbc-3.3.0.jar,bigQueryLoadingTemporaryDirectory=gs://iris-2-datastudio/input,username=SQLAdmin,password=Testing12!
Una vez que hayáis iniciado vuestra tarea, podéis disfrutar de la gloria de un trabajo bien hecho:

Echemos un vistazo a nuestros datos de origen y a la consulta en InterSystems Cloud SQL...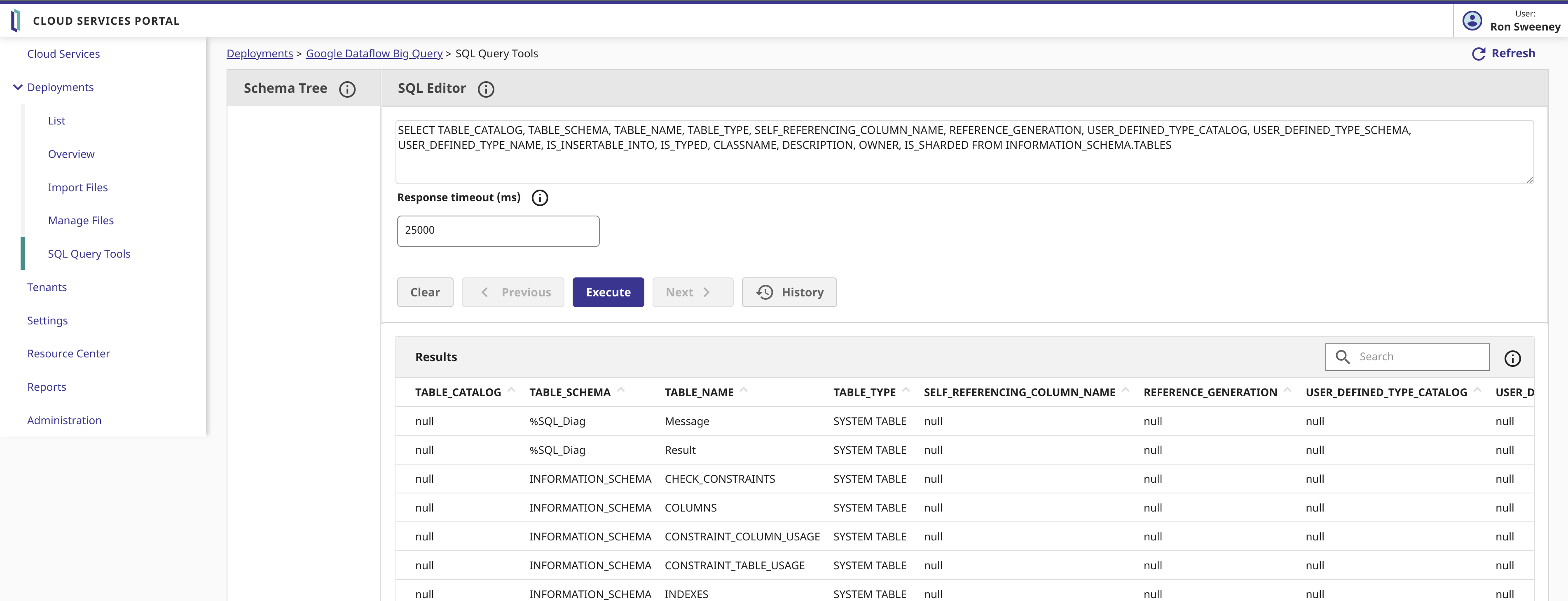
...y, después, examinando los resultados en Big Query, parece que, de hecho, tenemos InterSystems IRIS Data en Big Query.
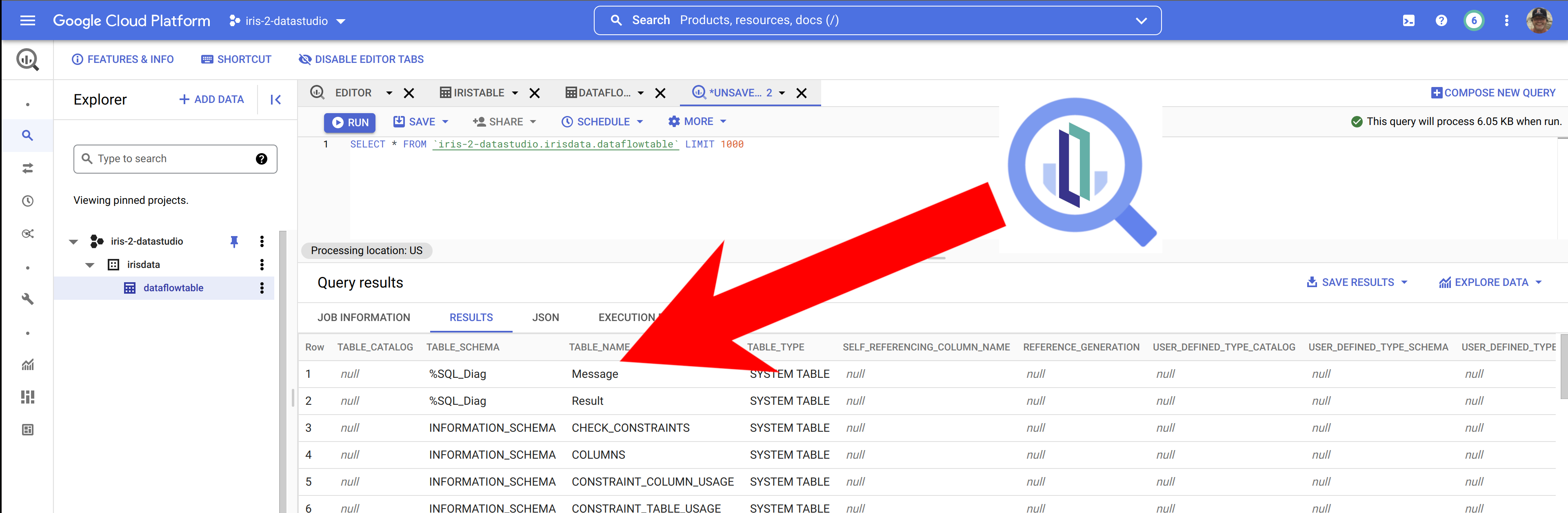
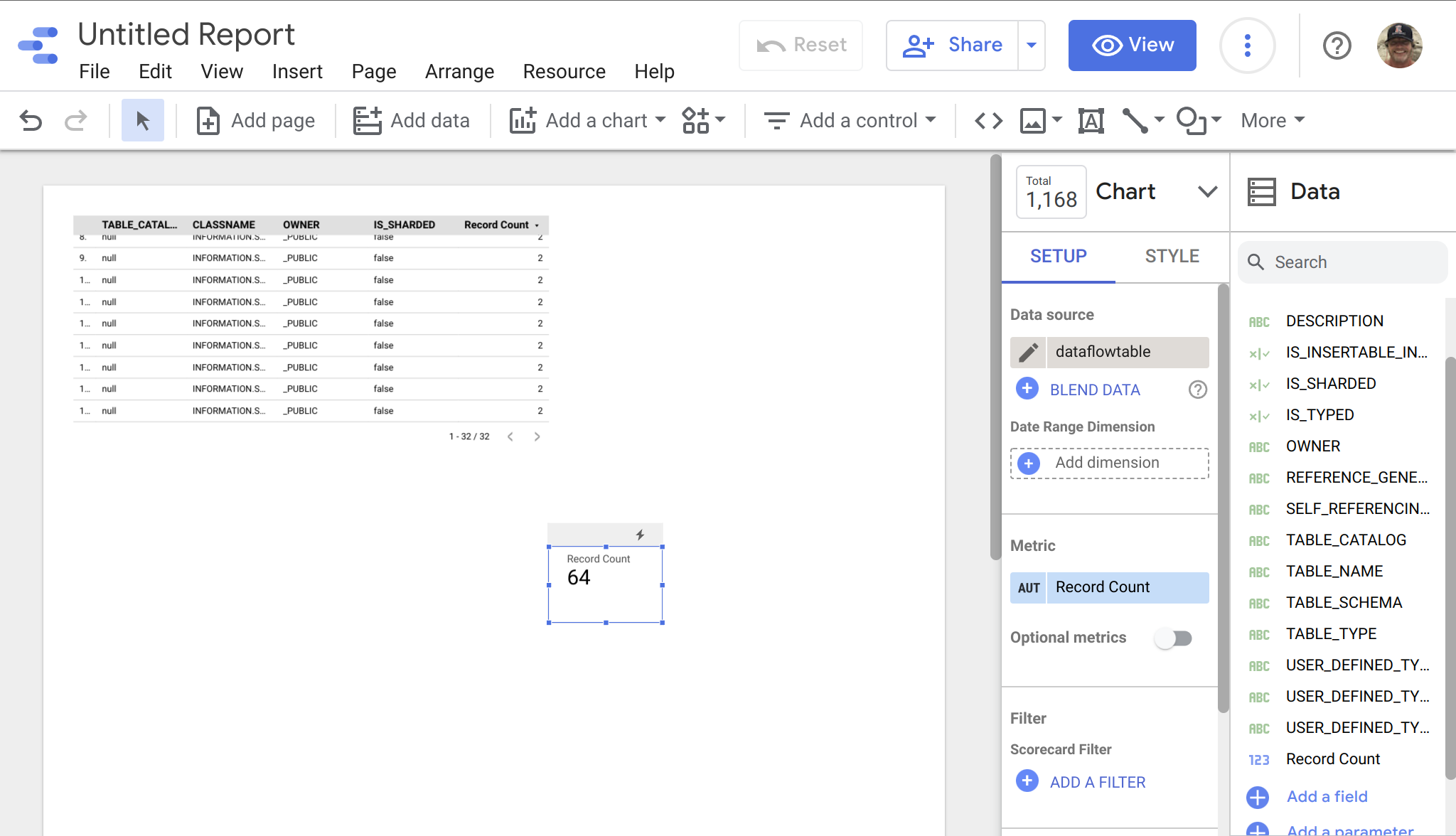
Cuando tengamos los datos en Big Query, es sencillo incluir nuestros datos de IRIS en Data Studio, seleccionando Big Query como fuente de datos... a este ejemplo de abajo le falta algo de estilo, pero se pueden ver rápidamente los datos de IRIS listos para su manipulación en vuestros proyectos en Data Studio.
Hoy en día es muy común que los datos que necesitas vengan de diferentes fuentes (e.g. aplicaciones externas e internas, distintas bases de datos y servicios, APIs, etc.). Además, seguro que tienes múltiples tipos de consumidores diferentes (e.g. usuarios finales, otras aplicaciones, servicios que publicas a terceros, etc.) y cada uno necesitará acceder a la información de forma diferente y para distintos objetivos. ¿Cómo construir una capa que de forma sencilla te permita gestionar estas necesidades? Hoy hablamos de Data Fabric 👈.

Un Enterprise Data Fabric realmente es una arquitectura que te ayuda a agilizar y simplificar el acceso a tus datos a lo largo de las distintas necesidades que tengas. Accede a datos de diferentes fuentes, los transforma y armoniza bajo demanda para hacerlos usables para diferentes patrones de consumo.
Es una arquitectura realmente interesante (¡y no lo digo sólo yo! 😄), de hecho en informes de Gartner aparece como "el futuro de la gestión de datos".
Smart Data Fabric sigue esta línea y añade además capacidades para incluir analytics, exploración de datos, explotación de algoritmos de machine learning directamente en esta capa y haciendo más fácil poder hacer análisis y construir aplicaciones. Y además es la visión que tenemos en InterSystems.
Comparto con vosotros un sencillo pero detallado ejemplo para que le echéis un vistazo directamente a algunas de las características de InterSystems IRIS que puede ayudaros a construir Smart Data Fabrics.
Si tenéis cualquier duda o aporte, por aquí estaré.
Apache Superset es una moderna plataforma para la visualización y exploración de datos. Superset puede reemplazar o aumentar las herramientas patentadas de business intelligence para muchos equipos. Y se puede integrar con una gran variedad de fuentes de datos.
¡Y ahora es posible utilizarla con InterSystems IRIS!
Hay disponible una demo online que usa IRIS Cloud SQL como fuente de datos.
.png)
Llamamos Procesamiento Híbrido Transaccional y Analítico (HTAP por sus siglas en inglés) a la capacidad de recuperar numerosos registros por segundo, mientras que a la vez se permiten consultas simultáneas en tiempo real. También se llama Analítica Transaccional ó Transanalítica y es un elemento muy útil en escenarios en los que disponemos de un flujo constante de datos en tiempo real, como podría ser el caso de datos provenientes de sensores IIOT o información de las fluctuaciones en el mercado bursátil y nos permite satisfacer la necesidad de consultar estos conjuntos de datos en tiempo real o casi en tiempo real.
Os comparto un ejemplo que podréis ejecutar en el que se recibe un conjunto de datos en streaming, con entradas de datos constantes y consultas continuas a la vez. El ejemplo está desarrollado en varias plataformas y podréis comparar cómo reaccionó cada una de ellas, con la velocidad de entrada y salida de datos en cada plataforma y su rendimiento. Las plataformas con las que he probado en esta demo son: InterSystems IRIS, MariaDB y MySQL.
Me gustaría compartir con la comunidad un log de datos de un servidor webde un cliente nuestro desde hace muchos años, una compañia operadora.
Su servidor web funciona sobre Apache y contiene datos útiles para analizar la carga y la actividad de los motores de búsqueda.
Tras instalar el proyecto, podrás ver los datos generados durante unos cuantos meses y que muestran la carga y la actividad típica de clientes, bots... también podrás ver cómo dicha carga depende del día de la semana, si son vacaciones o no, así como del momento del día.
El diseño del cubo se encuentra incluido en el paquete.
@José.Pereiray yo hemos creado un proyecto del que queremos hablar en este artículo.
IRIS RAD Studio es nuestra idea de una solución low-code para hacer más fácil la vida del desarrollador.
¿Y por qué no? Las aplicaciones low-code se han hecho muy populares últimamente. La imagen de abajo muestra el "Cuadrante mágico" ofrecido por la consultora Gartner para plataformas de aplicaciones low-code empresariales, y que muestra lo interesante que es este mercado.
Este artículo describe un diseño arquitectónico más flexible para DeepSee. Al igual que en el ejemplo anterior, esta implementación incluye bases de datos separadas para almacenar la memoria caché, la implementación y la configuración de DeepSee y la sincronización de los globals. Este ejemplo introduce una nueva base de datos para almacenar los índices de DeepSee. Redefiniremos los mapeos globales para que los índices de DeepSee no se mapeeen junto con las tablas de hechos y dimensiones.

Caso de Uso: tenemos acceso a datos remotos; vía JDBC o vía ODBC desde IRIS, y queremos presentar la información en un Dashboard, pero no deseamos o no podemos migrar dicha información a IRIS.
Alternativa: Tomamos ventaja de la conexión al origen de Datos, usamos "Linked Tables" de IRIS, luego podemos realizar el análisis a estos datos y presentarlos finalmente en un Dashboard.
Para este ejemplo vamos a realizarlo en este escenario:
¡Hola desarrolladores!
Os invitamos a un nuevo webinar en español: "Analítica de datos en FHIR. Del paciente a la población", el jueves 17 de noviembre, a las 3:00 PM (CET).
El webinar se retransmitirá en directo desde el Congreso "Iberia Summit" que InterSystems celebrará en Valencia la semana que viene.

Según la consultora IDC, el 80% de todos los datos producidos son NoSQL. Mira:
Hay documentos digitales y escaneados, textos online y offline, contenido BLOB (objeto binario grande) en SQL, imágenes, vídeos y audio. ¿Te imaginas una iniciativa de Analítica Corporativa sin todos estos datos para analizar y apoyar las decisiones?
En todo el mundo, muchos proyectos están utilizando tecnologías para transformar estos datos NoSQL en contenido de texto, para poder analizarlo. Fíjate:
Durante las últimas semanas, el equipo de Solution Architecture (Soluciones de Arquitectura) ha estado trabajando para terminar la carga de trabajo de 2019: esto incluyó la creación del código abierto de la Demostración de Readmisiones que llevó a cabo HIMSS el año pasado, para poder ponerla a disposición de cualquiera que busque una forma interactiva de explorar las herramientas proporcionadas por IRIS.
Durante el proceso de creación del código abierto de la demostración, nos encontramos de inmediato con un error crítico. Los datos subyacentes de los pacientes que se utilizaron para crear la demo no podían utilizarse como parte de un proyecto de código abierto porque no eran propiedad de InterSystems, eran propiedad de nuestro socio Baystate Health.
Nuestro equipo estaba en un pequeño aprieto y tenía que encontrar una forma de sustituir los datos originales por datos sintéticos que pudieran utilizarse, pero manteniendo la "historia" de las demos, o su funcionalidad subyacente, consistente. Dado que la demo muestra cómo IRIS admite el workflow de machine learning de un científico de datos, había un nivel de complejidad añadido porque cualquier dato que utilizáramos tenía que ser lo suficientemente realista como para poder apoyar nuestro modelo de investigación. Después de una breve investigación, Synthea vino a nuestro rescate.
Synthea es un generador de pacientes sintéticos, que modela sus historiales médicos. Es de código abierto. Synthea proporciona datos de alta calidad, realistas, pero no reales, de pacientes; en una variedad de formatos (incluido FHIR), con diferentes niveles de complejidad, cubriendo todos los aspectos de la atención médica. Los datos obtenidos no tienen coste, ni privacidad ni restricciones de seguridad, lo que permite investigar con datos de salud que de otra manera no estarían disponibles, de forma legal o práctica.
Después de una investigación inicial, se eligió Synthea como la herramienta para solucionar nuestro problema de datos. Synthea es una herramienta increíble; sin embargo, un problema que encontramos fue que, para ejecutar el software y obtener los pacientes, teníamos que instalar varias dependencias en nuestros equipos.
Cuando trabajas por tu cuenta, esto generalmente no es un problema, pero como nuestro equipo está formado por varias personas, es importante que todos puedan actualizarse con un nuevo software rápidamente; y la instalación de dependencias puede ser una pesadilla. Tenemos el propósito de que el menor número de personas posible sufra durante los procesos de instalación al integrar un nuevo software en nuestro flujo de trabajo.
Como necesitábamos que cualquier persona de nuestro equipo pudiera realizar actualizaciones en la Demo de readmisiones para poder generar pacientes fácilmente, y no queríamos que todos tuvieran que instalar Gradle en sus equipos, nos apoyamos en Docker e introdujimos el software de Synthea dentro de una imagen de Docker, permitiendo que la imagen se ocupe de las dependencias ambientales subyacentes.
Esto terminó funcionando muy bien para nuestro equipo, ya que nos dimos cuenta de que ser capaz de generar datos de pacientes sintéticos sobre la marcha es probablemente un caso de uso muy común al que se enfrentan nuestros compañeros Ingenieros de ventas, por lo que nuestro equipo quería compartirlo con la Comunidad de Desarrolladores.
Cualquiera puede utilizar la siguiente línea de código para generar rápidamente 5 historiales médicos de pacientes sintéticos en formato FHIR, y dejar los pacientes resultantes en una carpeta de salida en el directorio donde está trabajando actualmente.
Ahora estamos realizando actualizaciones para que el proyecto sea compatible con módulos personalizados, de modo que cualquiera que desee agregar una enfermedad a sus pacientes generados pueda hacerlo, si Synthea no la proporciona de forma predeterminada, y se incorporará automáticamente a su imagen.
¿Dónde se usa actualmente?
El proceso actual de creación de la Demo de readmisiones utiliza la imagen irisdemo-base-synthea para generar 5 000 pacientes sintéticos sobre la marcha y cargarlos en nuestro repositorio de datos IRIS relacional, normalizado. Cualquier persona que esté interesada en verificar cómo analizar estos datos de pacientes generados de forma sintética (en formato FHIR), puede consultar la Demo de readmisiones creada recientemente con código abierto. La clase que hay que buscar es: IRISDemo.DataLake.Utils. a partir de la línea 613.
La Demo de readmisiones se puede encontrar aquí: https://github.com/intersystems-community/irisdemo-demo-readmission
¡Hola Desarroladores!
IRIS External Table es un proyecto de código abierto de la comunidad de InterSystems, que permite utilizar archivos almacenados en el sistema de archivos local y almacenar objetos en la nube como AWS S3 y tablas SQL. 
Se puede encontrar en GitHub https://github.com/intersystems-community/IRIS-ExternalTable Open Exchange https://openexchange.intersystems.com/package/IRIS-External-Table y está incluido en el administrador de paquetes InterSystems Package Manager (ZPM).
Para instalar External Table desde GitHub, utilice:
git clone https://github.com/antonum/IRIS-ExternalTable.git
iris session iris
USER>set sc = ##class(%SYSTEM.OBJ).LoadDir("<path-to>/IRIS-ExternalTable/src", "ck",,1)
Para instalarlo con el ZPM Package Manager, utilice:
USER>zpm "install external-table"
Crearemos un archivo simple que tiene este aspecto:
a1,b1
a2,b2
Abra su editor favorito y cree el archivo o utilice solo una línea de comandos en Linux/Mac:
echo $'a1,b1\na2,b2' > /tmp/test.txt
Cree una tabla SQL en IRIS para representar este archivo:
create table test (col1 char(10),col2 char(10))
Convierta la tabla para utilizar el almacenamiento externo:
CALL EXT.ConvertToExternal(
'test',
'{
"adapter":"EXT.LocalFile",
"location":"/tmp/test.txt",
"delimiter": ","
}')
Y finalmente, consulte la tabla:
select * from test
Si todo funciona según lo previsto, debería ver el resultado de la siguiente forma:
col1 col2
a1 b1
a2 b2
Ahora regrese al editor, modifique el contenido del archivo y ejecute nuevamente la consulta SQL. ¡¡¡Tarán!!! Está leyendo nuevos valores de su archivo local en SQL.
col1 col2
a1 b1
a2 b99
En https://covid19-lake.s3.amazonaws.com/index.html puede acceder a los datos de la COVID que se actualizan constantemente, estos se almacenan por AWS en el lago de datos públicos.
Intentaremos acceder a una de las fuentes de datos en este lago de datos: s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states
Si tiene instalada la herramienta de línea de comandos para AWS, puede repetir los siguientes pasos. Si no es así, vaya directamente a la parte de SQL. No es necesario que tenga ningún componente específico de AWS instalado en su equipo para continuar con la parte de SQL.
$ aws s3 ls s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/
2020-12-04 17:19:10 510572 us-states.csv
$ aws s3 cp s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv .
download: s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv to ./us-states.csv
$ head us-states.csv
date,state,fips,cases,deaths
2020-01-21,Washington,53,1,0
2020-01-22,Washington,53,1,0
2020-01-23,Washington,53,1,0
2020-01-24,Illinois,17,1,0
2020-01-24,Washington,53,1,0
2020-01-25,California,06,1,0
2020-01-25,Illinois,17,1,0
2020-01-25,Washington,53,1,0
2020-01-26,Arizona,04,1,0
Por lo tanto, tenemos un archivo con una estructura bastante simple y cinco campos delimitados.
Para mostrar esta carpeta S3 como en External Table, primero necesitamos crear una tabla “regular” con la estructura deseada:
-- create external table
create table covid_by_state (
"date" DATE,
"state" VARCHAR(20),
fips INT,
cases INT,
deaths INT
)
Tenga en cuenta que algunos campos de datos como “Date” son palabras reservadas en el SQL de IRIS y deben escribirse entre comillas dobles. Entonces, necesitamos convertir esta tabla “regular” en la tabla “externa”, basada en el bucket AWS S3 y con el tipo CSV.
-- convert table to external storage
call EXT.ConvertToExternal(
'covid_by_state',
'{
"adapter":"EXT.AWSS3",
"location":"s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/",
"type": "csv",
"delimiter": ",",
"skipHeaders": 1
}'
)
Si observa detenidamente, en EXT.ExternalTable los argumentos de los procedimientos son el nombre de la tabla y luego la cadena JSON, además contiene varios parámetros como la ubicación para buscar archivos, el adaptador para utilizarlos, un delimitador, etc. Además, External Table de AWS S3 es compatible con el almacenamiento de Azure BLOB, Google Cloud Buckets y el sistema de archivos local. El repositorio de GitHub contiene referencias para la sintaxis y opciones que son compatibles con todos los formatos.
Y finalmente, consulte la tabla:
-- query the table
select top 10 * from covid_by_state order by "date" desc
[SQL]USER>>select top 10 * from covid_by_state order by "date" desc
2. select top 10 * from covid_by_state order by "date" desc
date state fips cases deaths
2020-12-06 Alabama 01 269877 3889
2020-12-06 Alaska 02 36847 136
2020-12-06 Arizona 04 364276 6950
2020-12-06 Arkansas 05 170924 2660
2020-12-06 California 06 1371940 19937
2020-12-06 Colorado 08 262460 3437
2020-12-06 Connecticut 09 127715 5146
2020-12-06 Delaware 10 39912 793
2020-12-06 District of Columbia 11 23136 697
2020-12-06 Florida 12 1058066 19176
Es comprensible que se necesite más tiempo para consultar los datos de la tabla remota, que para consultar la tabla “nativa de IRIS” o la tabla basada en el global, pero esta se almacena y actualiza completamente en la nube, y en segundo plano se extrae a IRIS.
Exploremos un par de funciones adicionales de External Table.
La carpeta de nuestro ejemplo, que se encuentra en el bucket, contiene solo un archivo. Lo más común es que tenga varios archivos de la misma estructura, donde el nombre del archivo identifique tanto al registro de la hora como al identificador de algún otro atributo que queramos utilizar en nuestras consultas.
El campo %PATH se agrega automáticamente a cada tabla externa y contiene la ruta completa hacia el archivo de donde se recuperó la fila.
select top 5 %PATH,* from covid_by_state
%PATH date state fips cases deaths
s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv 2020-01-21 Washington 53 1 0
s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv 2020-01-22 Washington 53 1 0
s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv 2020-01-23 Washington 53 1 0
s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv 2020-01-24 Illinois 17 1 0
s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv 2020-01-24 Washington 53 1 0
Puede utilizar el campo %PATH en sus consultas SQL como cualquier otro campo.
Si su tarea es cargar datos de S3 en una tabla IRIS, puede utilizar External Table como una herramienta ETL. Simplemente haga lo siguiente:
INSERT INTO internal_table SELECT * FROM external_table
En nuestro caso, si queremos copiar los datos COVID de S3 a la tabla local:
--create local table
create table covid_by_state_local (
"date" DATE,
"state" VARCHAR(100),
fips INT,
cases INT,
deaths INT
)
--ETL from External to Local table
INSERT INTO covid_by_state_local SELECT TO_DATE("date",'YYYY-MM-DD'),state,fips,cases,deaths FROM covid_by_state
External Table es una tabla SQL. Se puede unir con otras tablas, utilizarse en subconsultas y sistemas de archivos tipo UNION. Incluso puede combinar la tabla “Regular” de IRIS y dos o más tablas externas que provengan de diferentes fuentes en la misma consulta SQL.
Intente crear una tabla regular, por ejemplo, haga coincidir los nombres de los estados con sus códigos como en el caso de Washington y WA. Y únalos con nuestra tabla basada en S3.
create table state_codes (name varchar(100), code char(2))
insert into state_codes values ('Washington','WA')
insert into state_codes values ('Illinois','IL')
select top 10 "date", state, code, cases from covid_by_state join state_codes on state=name
Cambie “join” por “left join” para incluir aquellas filas donde el código del estado no esté definido. Como puede ver, el resultado es una combinación de datos provenientes de S3 y su tabla nativa de IRIS.
El lago de datos Covid en AWS es público. Cualquier persona puede leer los datos que provengan de esta fuente sin la necesidad de tener alguna autenticación o autorización. En la vida real seguramente quiere acceder a sus datos de una forma segura, donde se evite que extraños echen un vistazo a sus archivos. Los detalles completos sobre AWS Identity y Access Management (IAM) están fuera del alcance de este artículo. Pero lo mínimo que debe saber es que necesita por lo menos la clave de acceso a la cuenta y la información confidencial de AWS para acceder a los datos privados de su cuenta. https:
AWS utiliza la autenticación de claves/información confidencial de la cuenta para firmar las solicitudes. https://docs.aws.amazon.com/general/latest/gr/aws-sec-cred-types.html#access-keys-and-secret-access-keys
Si está ejecutando IRIS External Table en una instancia de EC2, la forma recomendada de lidiar con la autenticación es utilizando las funciones que se encuentran en la instancia de EC2 https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/iam-roles-for-amazon-ec2.html. De este modo, IRIS External Table podría utilizar los permisos de esa función. No se requiere ninguna configuración adicional.
En una instancia local o que no sea de EC2 es necesario especificar AWS_ACCESS_KEY_ID y AWS_SECRET_ACCESS_KEY, ya sea con la ayuda de variables de entorno o mediante la instalación y configuración del cliente CLI de AWS.
export AWS_ACCESS_KEY_ID=AKIAEXAMPLEKEY
export AWS_SECRET_ACCESS_KEY=111222333abcdefghigklmnopqrst
Asegúrese de que la variable de entorno sea visible dentro del proceso de IRIS. Puede verificarlo al ejecutar:
USER>write $system.Util.GetEnviron("AWS_ACCESS_KEY_ID")
Esto debería emitir el valor de la clave.
O instale el CLI de AWS, mediante instrucciones que se encuentran aquí: https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2-linux.html y ejecutar:
aws configure
Entonces External Table podrá leer las credenciales desde los archivos de configuración para el CLI de AWS. Posiblemente su shell interactivo y el proceso de IRIS estén ejecutándose en cuentas diferentes, asegúrese de ejecutar aws configure con la misma cuenta que su proceso de IRIS.
Acabo de redactar un ejemplo rápido para ayudar a un colega a cargar datos en IRIS desde R usando RJDBC y pensé que sería útil compartirlo aquí para futuras consultas.
Fue bastante sencillo, aparte de que a IRIS no le gusta el uso de puntos "." en los nombres de las columnas; la solución alternativa es simplemente renombrar las columnas. Alguien con más conocimientos que yo en R seguramente pueda ofrecer un enfoque más amplio ![]()
# Es necesario un valor válido para el JAVA_HOME antes de cargar la librería (RJDBC) Sys.setenv(JAVA_HOME="C:\\Java\\jdk-8.0.322.6-hotspot\\jre") library(RJDBC) library(dplyr) # Conexión a IRIS – se requiere la ruta a la librería JAR de InterSystems JDBC JAR de tu instalación drv <- JDBC("com.intersystems.jdbc.IRISDriver", "C:\\InterSystems\\IRIS\\dev\\java\\lib\\1.8\\intersystems-jdbc-3.3.0.jar","\"") conn <- dbConnect(drv, "jdbc:IRIS://localhost:1972/USER", "IRIS Username", "IRIS Password") dbListTables(conn) # Para mayor confusión, cargar el dataset de IRIS:) data(iris) # A IRIS no le gustan los puntos "." en el nombre de las columnas, así que los renombramos. (Probablemente se pueda codificar de una forma más genérica, pero no soy muy bueno con R.) iris <- iris %>% rename(sepal_length = Sepal.Length, sepal_width = Sepal.Width, petal_length = Petal.Length, petal_width = Petal.Width) # dbWriteTable/dbGetQuery/dbReadTable funcionan dbWriteTable(conn, "iris", iris, overwrite = TRUE) dbGetQuery(conn, "select count(*) from iris") d <- dbReadTable(conn, "iris")
Este artículo describe un diseño arquitectónico de complejidad intermedia para DeepSee. Al igual que en el ejemplo anterior, esta implementación incluye bases de datos separadas para almacenar la información, la implementación y la configuración de DeepSee. También presenta dos nuevas bases de datos: la primera para almacenar los globals necesarios para la sincronización, la segunda para almacenar tablas de hechos e índices.

En un mundo en constante cambio, las empresas deben innovar para ser competitivas. Esto asegura que tomarán decisiones con agilidad y seguridad, aspirando a obtener buenos resultados con mayor exactitud.
Las herramientas de Business Intelligence (BI) ayudan a las compañías a tomar decisiones inteligentes en vez de confiar en la "prueba y error". Estas decisiones inteligentes pueden ser la diferencia entre el éxito y el fracaso en el mercado.
Microsoft Power BI es una de las herramientas de Business Intelligence líderes. Con unos pocos clics, Power BI permite a los gerentes y analistas explorar los datos de la compañía. Esto es importante porque cuando es fácil accceder y visualizar los datos, es más probable que se usen para tomar decisiones.

InterSystems IRIS Business Intelligence te permite mantener actualizados tus modelos analíticos o cubos de varias formas. Este artículo tratará sobre Construir/Generar vs Sincronizar. Hay maneras de actualizar manualmente los cubos, pero son casos muy especiales y casi siempre los cubos se mantienen actualizados por medio de la (Re)construcción o la sincronización.
La interoperabilidad es uno de los temas más discutidos en los últimos años. Notamos cada vez más que nuestros datos de salud se comparten entre múltiples sistemas con el fin de acercar el concepto de salud del paciente.

Con InterSystems IRIS Adaptive Analytics puedes visualizar datos en tiempo real y representar analíticas, para poder tomar decisiones más inteligentes. Puedes conocer la herramienta en este vídeo general (3m) y realizar este curso online (2h).
¡Hola desarrolladores!
¿Sabéis cómo crear una solución de analítica de datos con InterSystems IRIS?

Para empezar, pongámonos de acuerdo sobre lo que es una solución de analítica de datos - este podría ser un tema muy amplio -. Por ello, acotaremos el conjunto de soluciones que se podían presentar al Concurso de Analítica de Datos.
Y a continuación examinaremos tres tipos de soluciones para analítica de datos: de monitorización, de análisis interactivo y de elaboración de informes (reporting).
Monitorización
La solución habitual de monitorización consiste en un cuadro de mando online con Indicadores Clave de Rendimiento (KPIs) que se actualizan constantemente.
El principal caso de uso de la monitorización es observar visualmente los KPIs de datos recientes todo el tiempo, para poder reaccionar ante una emergencia.
Análisis interactivo
Con esta solución, el usuario dispone de un conjunto de paneles de control interactivos con filtros y drill-downs que permiten ahondar en las categorías de información.
El principal caso de uso es explorar los datos con filtros y drill-downs para tomar decisiones de negocio a partir de la visualización de datos en gráficos y tablas.
Elaboración de informes
La solución para elaboración de informes ofrece un conjunto de informes (generalmente) estáticos, en forma de documentos HTML o PDF, que presentan los datos en forma de gráficos y texto en un formato predefinido y que pueden enviarse por correo electrónico.
El principal caso de uso habitual de un sistema de elaboración de informes es obtener informes de un periodo determinado, que permita ilustrar el estado del producto, el proceso, el servicio, las ventas, etc. lo que es crucial para la empresa.
¿Cómo se pueden utilizar los productos de InterSystems para crear estas soluciones? Comentemos esto más adelante.
Para visualizar la monitorización hay un conjunto de herramientas reconocidas y aceptadas por todo el sector. Entre ellas, Zabbix y Grafana son las más populares.
Grafana puede utilizarse como una herramienta de monitorización de datos en IRIS y el producto SAM de InterSystems utiliza Grafana para visualizar las métricas más importantes de un sistema IRIS específico. Además, puedes utilizar algunas soluciones desarrolladas por la comunidad para visualizar tus datos mediante Grafana, por ejemplo, esta.
El enfoque más habitual para crear una solución de análisis interactivo es configurar un cubo analítico con dimensiones y medidas específicas; y a continuación, utilizar la herramienta para configurar cuadros de mando basados en el cubo. Hay dos herramientas de InterSystems IRIS que se pueden utilizar para ello: IRIS BI y Adaptive Analytics.
Para empezar, asumimos que ya cuentas con un servidor de InterSystems IRIS con los datos para los que quieres crear la solución analítica. Hay diversas formas de importar datos a tu servidor de IRIS, por ejemplo, a partir de un controlador ODBC/JDBC o con el módulo csvgen o csvgen-ui, o bien con la instalación de paquetes zpm con datos, como samples-bi o dataset-titanic.
IRIS BI
Con IRIS BI se pueden crear cubos de IRIS BI mediante IRIS BI Architect. Se puede alojar en el mismo equipo en que está instalado IRIS o en otro separado, en caso de que se requiera un mayor rendimiento. A continuación, se pueden crear pivots o tablas dinámicas (MDX) y KPIs (SQL) utilizando IRIS BI Analyzer como fuentes de datos y después crear los cuadros de mando interactivos de IRIS BI para visualizar los datos de estas fuentes de datos. Se pueden alojar en el mismo servidor de IRIS o en otro distinto. La alternativa a los cuadros de mando de IRIS BI podría ser el uso de MDX2JSON, que proporciona una API de JSON para los pivots y los datos podrían visualizarse con la herramienta DeepSee Web o con cualquier framework frontend JS que utilice JSON.
Estos son algunos ejemplos de este tipo de soluciones: Samples BI (online, User namespace, repositorio), Covid-19 (online, repositorio), y Juego de Tronos (online, User namespace, repositorio).



Adaptive Analytics
También puedes crearlo con InterSystems Adaptive Analytics. Se usaría AtScale para configurar un cubo virtual alojado en el servidor AtScale conectado con el servidor de datos de IRIS BI. Una vez tengas configurado el servidor de AtScale, puedes crear cuadros de mando interactivos utilizando cualquier herramienta que se pueda usar para crear paneles de control interactivos, como Tableau, PowerBI o Excel. Echa un vistazo a este ejemplo de una solución de Adaptive Analytics y la historia.
.png)
Cómo crear una solución de elaboración de informes
La solución de elaboración de informes se puede crear con la solución InterSystems Reports. Necesitarás Logi Composer para crear informes que se conecten a IRIS mediante el driver JDBC y, a continuación, entregar los informes con un servidor de informes Logi. Puedes gestionar contenedores de Docker para alojar el servidor de informes Logi, como se describe aquí.
Echa un vistazo a este artículo sobre InterSystems Reports y cómo ejecutar Reports Server en un contenedor de Docker.
¡Desarrolladores! ¿Qué os parece? Por supuesto, también se podría mencionar iKnow, PMML, IntegratedML, Embedded Python y Apache Spark.
¡Os invito a que compartáis vuestra experiencia creando este u otro enfoque analítico con IRIS.
¡Hola Comunidad!
Hemos grabado el webinar que hicimos ayer y lo hemos subido al canal de YouTube de la Comunidad de Desarrolladores en español. Si os perdisteis el webinar o lo queréis volver a ver con más detalle, ya está disponible la grabación!
Alberto Fuentes es uno de los cracks de InterSystems. Así que... si queréis saber todo sobre la Analítica de datos y el Reporting, ¡no os perdáis el vídeo!
¡Hola desarrolladores!
Os invitamos a un nuevo webinar en español: "Self-Service Analytics & Reporting", el miércoles 17 de noviembre, a las 4:00 PM (CET).

El webinar está dirigido a aquellos perfiles involucrados en proyectos de Analítica de Datos y Business Intelligence.
Durante la presentación, aprenderás a construir entornos que incorporen Self-Service Analytics, empleando herramientas como Tableau, PowerBI y Excel. También aprenderás a generar informes con una solución para Reporting.