
Estoy muy emocionado de continuar con mi serie de artículos "InterSystems para Dummies", y hoy queremos contarles todo sobre una de las funciones más potentes que tenemos para la interoperabilidad.
Aunque ya las hayan probado, planeamos analizar a fondo cómo sacarles el máximo provecho y mejorar aún más nuestra producción.
¿Qué es Record Mapper?
En esencia, un Record Mapper es una herramienta que permite mapear datos de archivos de texto a mensajes de producción y viceversa. La interfaz del Portal de Administración, por otro lado, permite crear una representación visual de un archivo de texto y un modelo de objeto válido de esos datos para mapearlos a un único objeto de mensaje de producción persistente.
Por lo tanto, si desea importar datos de un archivo CSV a su clase persistente, puede probar con un par de clases entrantes (por FTP o directorio de archivos). ¡Pero no se apresure! Abordaremos cada uno de estos puntos a su debido tiempo.
TIP: Todos los ejemplos y clases descritos en este artículo se pueden descargar desde el siguiente enlace: https://github.com/KurroLopez/iris-recordmap-fordummies.git
¿Cómo empezar?
Vayamos al grano y especifiquemos nuestro escenario.
Necesitamos importar información de nuestros clientes, incluyendo su nombre, fecha de nacimiento, número de identificación nacional, dirección, ciudad y país.
Abra su portal IRIS y seleccione Interoperabilidad – Crear – Record Maps.

Cree un nuevo Record Maps con el nombre del paquete y la clase.
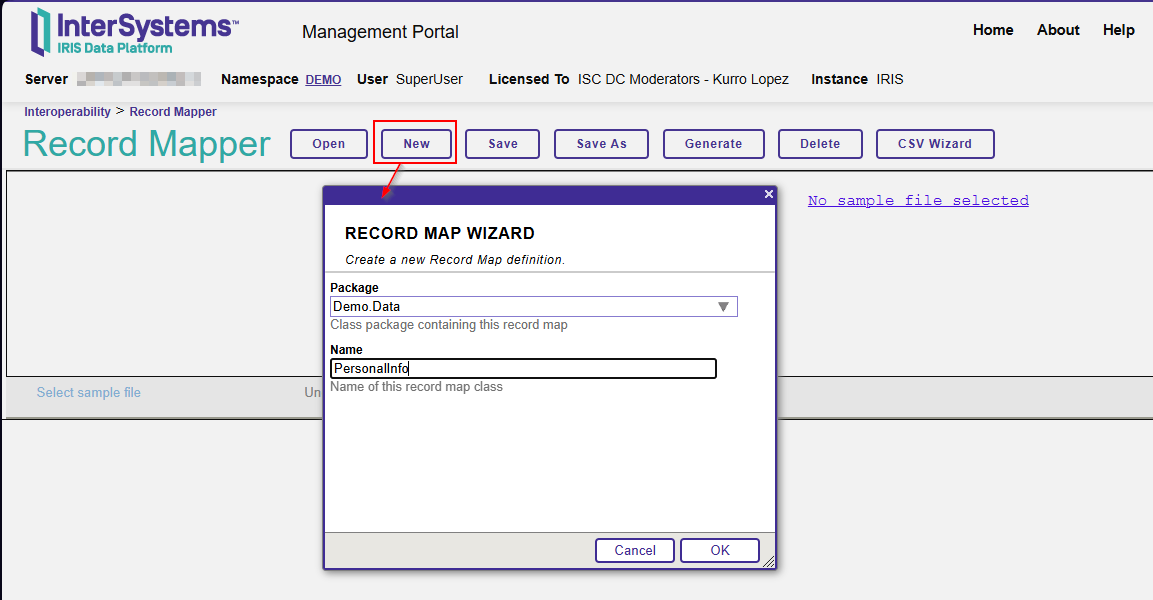
En nuestro ejemplo, el nombre del paquete es Demo.Data, mientras que el nombre de la clase es PersonalInfo.
El primer paso es configurar el archivo CSV. Esto significa determinar el carácter separador, si los campos de cadena tienen comillas dobles, etc.

Si usa el sistema operativo Windows, el terminador de registro común es CRLF (Char(10) Char(12)).
Como mi archivo CSV es estándar, separado por punto y coma (;), debo definir el carácter del separador de campos.
Ahora, voy a declarar los campos del perfil del cliente (nombre, apellidos, fecha de nacimiento, número de identificación nacional, dirección, ciudad y país).

Esta es una definición básica, pero puedes establecer más condiciones con respecto a tu archivo CSV si lo deseas.

Recuerda que, por defecto, un campo %String tiene una longitud máxima de 50 caracteres. Por lo tanto, actualizaré este valor para permitir más caracteres en el campo de dirección (un máximo de 100).
También definiré el formato de fecha usando el formato ISO (aaaa-mm-dd), que corresponde al número 3.
Además, haré obligatorios los campos de nombre, apellido y fecha de nacimiento.

¡Listo! ¡Presionemos el botón "Generar" para crear la clase persistente!

Let's take a look at the generated class:
/// THIS IS GENERATED CODE. DO NOT EDIT.<br/>
/// RECORDMAP: Generated from RecordMap 'Demo.Data.PersonalInfo'
/// on 2025-07-14 at 08:37:00.646 [2025-07-14 08:37:00.646 UTC]
/// by user SuperUser
Class Demo.Data.PersonalInfo.Record Extends (%Persistent, %XML.Adaptor, Ens.Request, EnsLib.RecordMap.Base) [ Inheritance = right, ProcedureBlock ]
{
Parameter INCLUDETOPFIELDS = 1;
Property Name As %String [ Required ];
Property Surname As %String [ Required ];
Property DateOfBirth As %Date(FORMAT = 3) [ Required ];
Property NationalId As %String;
Property Address As %String(MAXLEN = 100);
Property City As %String;
Property Country As %String;
Parameter RECORDMAPGENERATED = 1;
Storage Default
{
<Data name="RecordDefaultData">
<Value name="1">
<Value>%%CLASSNAME</Value>
</Value>
<Value name="2">
<Value>Name</Value>
</Value>
<Value name="3">
<Value>%Source</Value>
</Value>
<Value name="4">
<Value>DateOfBirth</Value>
</Value>
<Value name="5">
<Value>NationalId</Value>
</Value>
<Value name="6">
<Value>Address</Value>
</Value>
<Value name="7">
<Value>City</Value>
</Value>
<Value name="8">
<Value>Country</Value>
</Value>
<Value name="9">
<Value>Surname</Value>
</Value>
</Data>
<DataLocation>^Demo.Data.PersonalInfo.RecordD</DataLocation>
<DefaultData>RecordDefaultData</DefaultData>
<ExtentSize>2000000</ExtentSize>
<IdLocation>^Demo.Data.PersonalInfo.RecordD</IdLocation>
<IndexLocation>^Demo.Data.PersonalInfo.RecordI</IndexLocation>
<StreamLocation>^Demo.Data.PersonalInfo.RecordS</StreamLocation>
<Type>%Storage.Persistent</Type>
}
}
Como puede ver, cada propiedad tiene el nombre de los campos en nuestro archivo CSV.
En este punto, crearemos un archivo CSV con la siguiente estructura para probar nuestro Record Mapper:
Name;Surname;DateOfBirth;NationalId;Address;City;Country Matthew O.;Wellington;1964-31-07;208-36-1552;1485 Stiles Street;Pittsburgh;USA Deena C.;Nixon;1997-03-03;495-26-8850;1868 Mandan Road;Columbia;USA Florence L.;Guyton;2005-04-10;21 069 835 790;Invalidenstrasse 82;Contwig;Germany Maximilian;Hahn;1945-10-17;92 871 402 258;Boxhagener Str. 97;Hamburg;Germany Amelio;Toledo Zavala;1976-06-07;93789292F;Plaza Mayor, 71;Carbajosa de la Sagrada;Spain
Puedes usarlo como prueba ahora.
Haz clic en "Seleccionar archivo de muestra", selecciona la muestra en /irisrun/repo/Samples y elige PersonalInfo-Test.csv.

En este momento podrás observar cómo se importan tus datos:

Los problemas crecen
Justo cuando crees que todo está listo, recibes una nueva especificación de tu jefe:
"Necesitamos los datos para poder cargar el número de teléfono del cliente y almacenar más de uno (fijo, móvil, etc.)".
Uy... Necesito actualizar mi Record Map y agregar un número de teléfono. Sin embargo, debería tener más de uno... ¿Cómo puedo hacerlo?
Nota: Puedes hacerlo directamente en la misma clase. Sin embargo, crearé una nueva para fines explicativos y la guardaré en los ejemplos. De esta manera, puedes revisar y ejecutar el código siguiendo todos los pasos de este artículo.
Bien, es hora de reabrir el Record Map que acabamos de crear.
Agrega el nuevo campo "Phone", pero recuerda indicar que este campo es "Repetido".

Dado que hemos asignado este campo como "Repetido", debemos definir el carácter separador para los datos replicados. Este indicador se encuentra en el mismo lugar donde normalmente especificamos el separador de campo.

¡Perfecto! Carguemos el archivo CSV de ejemplo con los números de teléfono separados por #.

Si echamos un vistazo a la clase persistente que hemos producido, podemos ver que el campo "Phone" es de tipo Lista de %String:
Property Phone As list Of %String(MAXLEN = 20);
Ok, Kurro, pero ¿Cómo podemos subir este archivo?
Es una muy buena pregunta, querido lector.
Intersystems IRIS nos proporciona dos clases de entrada:
EnsLib.RecordMap.Service.FileServiceEnsLib.RecordMap.Service.FTPService
No profundizaré en estas clases porque sería demasiado largo. Sin embargo, podemos revisar sus funciones principales.
En resumen, el servicio monitoriza los procesos en una carpeta definida, captura los archivos almacenados en ese directorio, los carga, los lee línea por línea y envía ese registro al proceso de negocio designado.
Esto ocurre tanto en el servidor como en los directorios FTP.
Vayamos al grano…
Nota: Presentaré mis ejemplos utilizando la clase EnsLib.RecordMap.Service.FileService. Sin embargo, la clase EnsLib.RecordMap.Service.FTPService realiza las mismas operaciones.
Si ha descargado el código de ejemplo, verás que se ha creado una producción con dos componentes:
Una clase de servicio (EnsLib.RecordMap.Service.FileService), que cargará los archivos, y una clase de negocio (Demo.BP.ProcessData), que procesará cada uno de los registros leídos del archivo. En este caso, usaremos este último solo para ver los rastros de comunicación.
Es importante configurar algunos parámetros en la clase del Business Service.

File Path: Es un registro que la clase utiliza para monitorear si hay archivos pendientes de procesamiento. Al colocar un archivo en este directorio, el proceso de carga se activa automáticamente y envía cada registro a la clase definida como Business Process.
File Spec: Es un patrón de archivo para buscar (por defecto, es *, pero podemos definir algunos archivos que deseamos diferenciar de otros procesos). Por ejemplo, podemos tener dos clases de escucha entrantes en el mismo directorio, cada una con una clase RecordMap diferente. Podemos asignar la extensión .pi1 a los archivos que procesará la clase PersonalInfo, mientras que .pi2 marcará los archivos que serán procesados por la clase PersonalInfoPhone.
Archive Path: Es un directorio donde se mueven los archivos después de ser procesados.
Work Path: Es una ruta donde el adaptador debe colocar el archivo de entrada mientras procesa los datos. Esta configuración es útil cuando se usa el mismo nombre de archivo para envíos repetidos. Si no se especifica WorkPath, el adaptador no moverá el archivo durante el procesamiento.
Call Interval: Es la frecuencia (calculada en segundos) de las comprobaciones del adaptador para los archivos de entrada en las ubicaciones especificadas.
RecordMap: Es el nombre de la clase Record Map, que contiene la definición de los datos en el archivo.
Target Config Name: Es el nombre del Proceso de Negocio que maneja los datos almacenados en el archivo.

Subdirectory Levels: Es un espacio donde el proceso busca un nuevo archivo. Por ejemplo, si un proceso añade un archivo cada día (lunes, martes, miércoles, jueves y viernes), buscará en todos los subdirectorios, comenzando por el directorio raíz, siempre que especifiquemos el nivel 1. Por defecto, el nivel 0 significa que solo buscará en el directorio raíz.
Delete From Server: Esta función indica que si no se especifica el directorio de los archivos procesados, el archivo se eliminará del directorio raíz.
File Access Timeout: Es un tiempo definido (calculado en segundos) para acceder al archivo. Si el archivo es de solo lectura o hay algún problema que impida el acceso al directorio, se mostrará un error.
Header Count: Es una característica importante que indica el número de encabezados que se deben ignorar. Por ejemplo, si el archivo tiene un encabezado que especifica los campos que contiene, debe indicar cuántas líneas de encabezado contiene para que se puedan ignorar y solo se puedan leer las líneas de datos.
Subir un archivo
Como mencioné anteriormente, el proceso de carga se activa cuando se coloca un archivo en el directorio del proceso.
Nota: Las siguientes instrucciones se basan en el código de ejemplo.
En la carpeta "samples", encontrará el archivo PersonalInfoPhone-Test.csv. Debe copiar este archivo a la carpeta del proceso para que se procese automáticamente.
NOTA: Si está trabajando con Docker, use el siguiente comando:
docker cp .\PersonalInfoPhone-Test.csv containerId:/opt/irisbuild/process/containerId es el ID de su contenedor, ej: docker cp .\PersonalInfoPhone-Test.csv 66f96b825d43398ba6a1edcb2f02942dc799d09f1b906627e0563b1392a58da1:/opt/irisbuild/process/`

Para cada registro, lanza una llamada al proceso de negocio con todos los datos.

¡Excelente trabajo! En tan solo unos pasos, lograste crear un proceso que puede leer archivos de un directorio y administrar esos datos de forma rápida y sencilla.
¿Qué más podrías pedir a tus procesos de interoperabilidad?
Complex Record Map
Nadie quiere tener una vida compleja, pero te prometo que te enamorarás de los Complex Record Map .
Los Complex Record Map son precisamente lo que su nombre indica. Se trata de una combinación de varios Record Maps que nos proporciona información más completa y estructurada.
Imaginemos que nuestro jefe nos contacta y nos plantea los siguientes requisitos:
“Necesitamos información del cliente con más números de teléfono, incluyendo códigos de país y prefijos. También necesitamos más direcciones de contacto, incluyendo códigos postales, países y nombres de estados.
Un cliente puede tener un número de teléfono, dos o ninguno”.
Si necesitamos más información sobre números de teléfono y direcciones, como hemos visto anteriormente, incluir esta información en una sola línea sería demasiado complicado. Separemos las diferentes partes que necesitamos:
- Información del cliente requerida.
- Números de teléfono (del 0 al 5).
- Dirección postal (del 0 al 2).
Para cada sección, crearemos un alias para diferenciar el tipo de información que incluye.
Construyamos cada sección:
Paso 1
Diseña un nuevo Record Maps para la información del cliente (Nombre, Apellidos, Fecha de Nacimiento y Documento Nacional de Identidad) e incluya un identificador para indicar que se trata de la sección USER.

El nombre de la sección debe ser único para los tipos de datos "USER", ya que son responsables de configurar las columnas y posiciones de cada dato.
El contenido debería ser similar al siguiente:
USER|Matthew O.;Wellington;1964-07-31;208-36-1552
En NEGRITA, el nombre de la sección, en CURSIVA, el contenido.
Paso 2
Crea las secciones PHONE y ADDRESS para los números de teléfono y las direcciones postales.
Recuerda especificar el nombre de la sección y activar la opción Complez Record Map.


Ahora deberíamos tener tres clases:
- Demo.Data.ComplexUser
- Demo.Data.ComplexPhone
- Demo.Data.ComplexAddress
Paso 3
Completa el Complex Record Map.
Abre la opción "Complex Record Maps":

Lo primero que vemos aquí es una estructura con un encabezado y un pie de página. El encabezado puede ser otro mapa de registros para almacenar información del paquete de datos (por ejemplo, información del departamento del usuario, etc.).
Dado que estas secciones son opcionales, las ignoraremos en nuestro ejemplo.

Establezca el nombre de este registro (por ejemplo, PersonalInfo) y agregue nuevos registros para cada sección.

Si deseamos que uno de los apartados tenga repeticiones, deberemos indicar los valores mínimos y máximos de repetición.

De acuerdo a las especificaciones anteriores, el archivo con la información lucirá así:
USER|Matthew O.;Wellington;1964-07-31;208-36-1552
PHONE|1;305;2089160
PHONE|1;805;9473136
ADDR|1485 Stiles Street;Pittsburgh;15286;PA;USA
Si queremos cargar un archivo, necesitamos un servicio que pueda leer este tipo de archivos, e Intersystems IRIS nos proporciona dos clases de entrada para eso:
EnsLib.RecordMap.Service.ComplexBatchFileServiceEnsLib.RecordMap.Service.ComplexBatchFTPService
Como mencioné anteriormente, usaremos la clase EnsLib.RecordMap.Service.ComplexBatchFileService como ejemplo. Sin embargo, el proceso para FTP es idéntico.
Utiliza la misma configuración que el Record Map, excepto por el número de línea del encabezado, porque este tipo de archivo no necesita uno:

Como mencioné anteriormente, el proceso de carga se activa cuando se coloca un archivo en el directorio del proceso.
Nota: Las siguientes instrucciones se basan en el código de ejemplo.
En la carpeta "samples", encontrará el archivo PersonalInfoComplex.txt. Debe copiar este archivo a la carpeta del proceso para que se procese automáticamente.
NOTA: Si trabaja con el ejemplo de Docker, utilice el siguiente comando:
docker cp .\ PersonalInfoComplex.txt containerId:/opt/irisbuild/process/p
containerId es el id de su contenedor, ex: docker cp .\ PersonalInfoComplex.txt 66f96b825d43398ba6a1edcb2f02942dc799d09f1b906627e0563b1392a58da1:/opt/irisbuild/process/
Aquí podemos ver cada fila llamando al Business Service:



Como ya se habrá dado cuenta, los Record Maps son una herramienta potente para importar datos de forma compleja y estructurada. Permiten guardar información en tablas relacionadas o procesar cada dato de forma independiente.
Gracias a esta herramienta, puede crear rápidamente procesos de carga de datos por lotes y almacenarlos sin necesidad de realizar lecturas complejas de datos, separación de campos, validación de tipos de datos, etc.
Espero que este artículo le sea útil.
Nos vemos en el próximo "InterSystems para Dummies".


.jpg)




.png)



.png)
