
Hola Comunidad,
En este artículo voy a enseñar diferentes usos de InterSystems Embedded Python. Vamos a cubrir los siguientes temas:
- 1-Visión general de Embedded Python
- 2-Uso de Embedded Python
- 2.1 - Uso de una biblioteca Python desde ObjectScript
- 2.2 - Llamando a las API de InterSystems desde Python
- 2.3 - Uso conjunto de ObjectScript y Python
- 3-Uso de las funciones incorporadas de python
- 4-Módulos o bibliotecas de Python
- 5-Casos de uso de Embedded Python
- 5.1- Imprimir PDF usando python Biblioteca Reportlab
- 5.2- Generación de código QR mediante el uso de Python Biblioteca Qrcode
- 5.3- Obtener la geolocalización usando Python Biblioteca Folium
- 5.4- Generar y marcar ubicaciones en un Mapa interactivo utilizando Biblioteca Folium de Python
- 5.5- Análisis de datos mediante el uso de Python Biblioteca Pandas
- 6-Resumen
Empecemos con un resumen

1-Resumen de Embedded Python
Embedded Python es una característica de la plataforma de datos de InterSystems IRIS que permite a los desarrolladores de Python obtener un acceso completo y directo a los datos y a la funcionalidad de InterSystems IRIS.
InterSystems IRIS incluye con un potente lenguaje de programación incorporado llamado ObjectScript que se interpreta, compila y ejecuta dentro de la plataforma de datos.
Dado que ObjectScript se ejecuta dentro del contexto de InterSystems IRIS, tiene acceso directo a la memoria y a las llamadas a procedimientos de la plataforma de datos.
Embedded Python es una extensión del lenguaje de programación Python que permite la ejecución de código Python dentro del contexto del proceso InterSystems IRIS.
Dado que tanto ObjectScript como Python operan sobre la misma memoria de objetos, puede decirse que los objetos Python no sólo emulan objetos ObjectScript, sino que son objetos ObjectScript.
La coigualdad de estos lenguajes permite que podáis elegir el lenguaje más apropiado para el trabajo, o el lenguaje con el que os sintáis más cómodos para escribir aplicaciones.

2-Uso de Embedded Python
Al utilizar Embedded Python, podéis escribir código en tres modalidades diferentes.
2.1 - Uso de una biblioteca Python desde ObjectScript
En primer lugar, podéis escribir un archivo .py ordinario y llamarlo desde el contexto InterSystems IRIS. En este caso, la plataforma de datos lanzará el proceso de Python y os permitirá importar un módulo llamado IRIS, que asocia automáticamente el proceso de Python al núcleo de IRIS y os proporciona acceso a toda la funcionalidad de ObjectScript desde el contexto de vuestro código Python..png)
2.2 - Llamando a las API de InterSystems desde Python
En segundo lugar, podéis escribir un código ObjectScript ordinario e instanciar un objeto Python utilizando el paquete %SYS.Python. Este paquete ObjectScript os permite importar módulos y bibliotecas de Python y, a continuación, trabajar con esa base de código utilizando la sintaxis ObjectScript.
El paquete %SYS.Python permite a los desarrolladores de ObjectScript sin ningún conocimiento de Python utilizar el rico ecosistema de bibliotecas Python en su código ObjectScript..png)
2.3 - Uso conjunto de ObjectScript y Python
En tercer lugar, podéis crear una definición de clase de InterSystems y escribir métodos en Python. Cualquier llamada a ese método lanzará el intérprete de Python. Este método tiene la ventaja de poblar la palabra clave self de ese bloque de código Python con una referencia a la instancia de la clase contenedora. Además, al utilizar Python para escribir métodos de clase en las clases de InterSystems, podéis implementar fácilmente métodos que administren diferentes eventos de entrada de datos en SQL, como la adición de una nueva fila a una tabla.
También permite desarrollar rápidamente procedimientos almacenados personalizados en Python.
.png)
Como podéis ver, Embedded Python os permite elegir el lenguaje de programación más adecuado para el trabajo sin sacrificar el rendimiento.

3-Uso de las funciones incorporadas de Python
El intérprete de Python tiene una serie de funciones y tipos incorporados que están siempre disponibles. Se enumeran aquí por orden alfabético.
| Funciones incorporadas | |||
|---|---|---|---|
A
B
C
D
| E
F
G
H
I | L
M
N
O
P
| R
S
T
V
Z
_ |
Uso de las funciones incorporadas de python
Para utilizar una función incorporada de python tenemos que importar "builtins" y después podremos llamar a la función
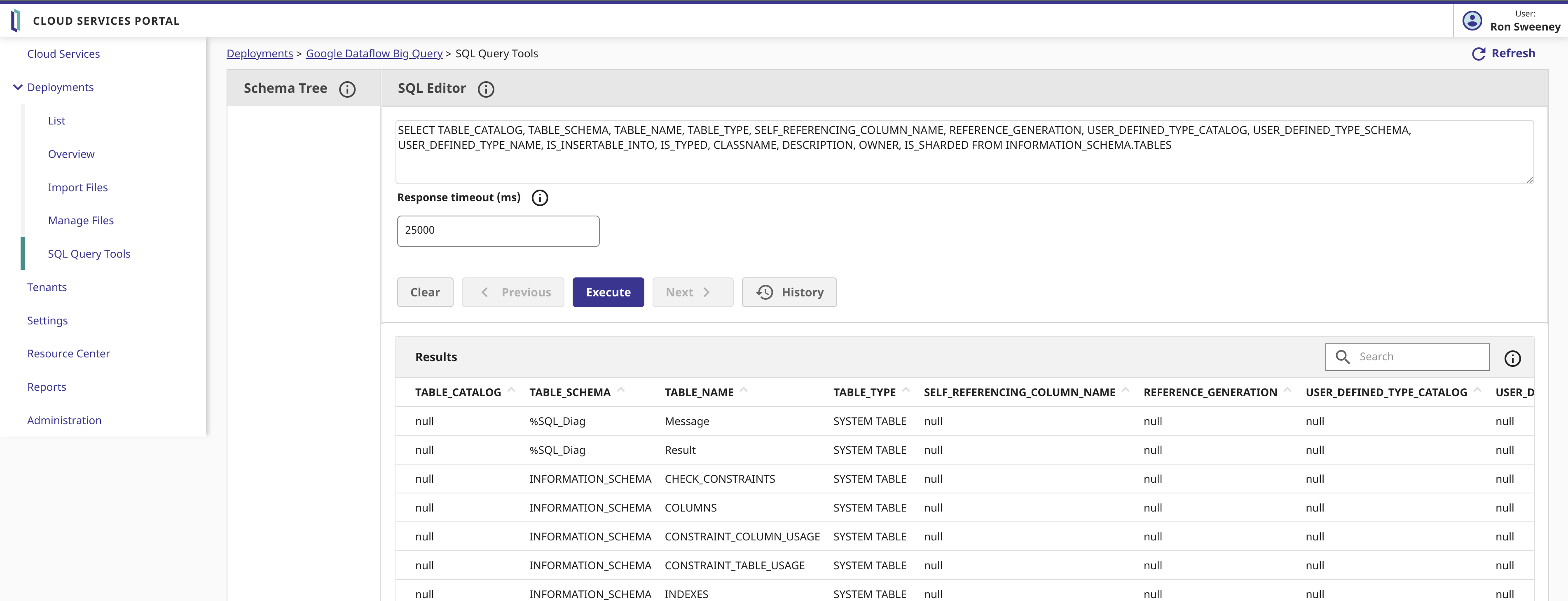
set builtins = ##class(%SYS.Python).Import("builtins")La función print() de python es en realidad un método del módulo incorporado, por lo que ahora podéis utilizar esta función desde ObjectScript:
USER>do builtins.print("hello world!")
hello world!USER>set list = builtins.list()
USER>zwrite list
list=5@%SYS.Python ; [] ; Del mismo modo, podéis utilizar el método help() para obtener ayuda sobre el objeto lista.
USER>do builtins.help(list)
Help on list object:
class list(object)
| list(iterable=(), /)
|
| Built-in mutable sequence.
|
| If no argument is given, the constructor creates a new empty list.
| The argument must be an iterable if specified.
|
| Methods defined here:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
|
| __delitem__(self, key, /)
| Delete self[key].

4-Módulos o bibliotecas python
Algunos módulos o bibliotecas de Python se instalan de forma predeterminada y ya están disponibles para su uso. Utilizando la función help("module" podemos ver estos módulos: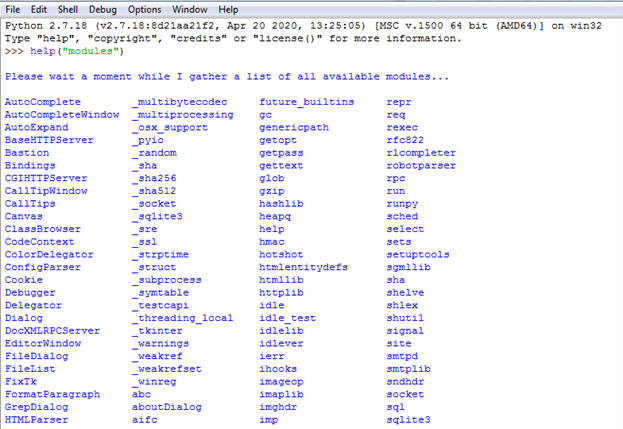

Instalación de un módulo o biblioteca de Python
Además de estos módulos en Python existen cientos de módulos o bibliotecas, que se pueden consultar en pypi.org(The Python Package Index (PyPI) es un repositorio de software para el lenguaje de programación Python)
.png)
Si necesitamos algunas otras bibliotecas, entonces necesitamos instalar las bibliotecas usando el comando intersystems irispip
Por ejemplo, Pandas es una biblioteca de análisis de datos de Python. El siguiente comando utiliza el instalador de paquetes irispip para instalar pandas en un sistema Windows:
C:\InterSystems\IRIS\bin>irispip install --target C:\InterSystems\IRIS\mgr\python pandasTened en cuenta que C:\InterSystems será sustituido por el directorio de instalación de Intersystems
5-Casos de uso de Embedded Python
5.1-Imprimir PDF utilizando la biblioteca Reportlab de python
Necesitamos instalar la biblioteca Reportlab usando el comando irispip, luego simplemente crear la función objectcript.
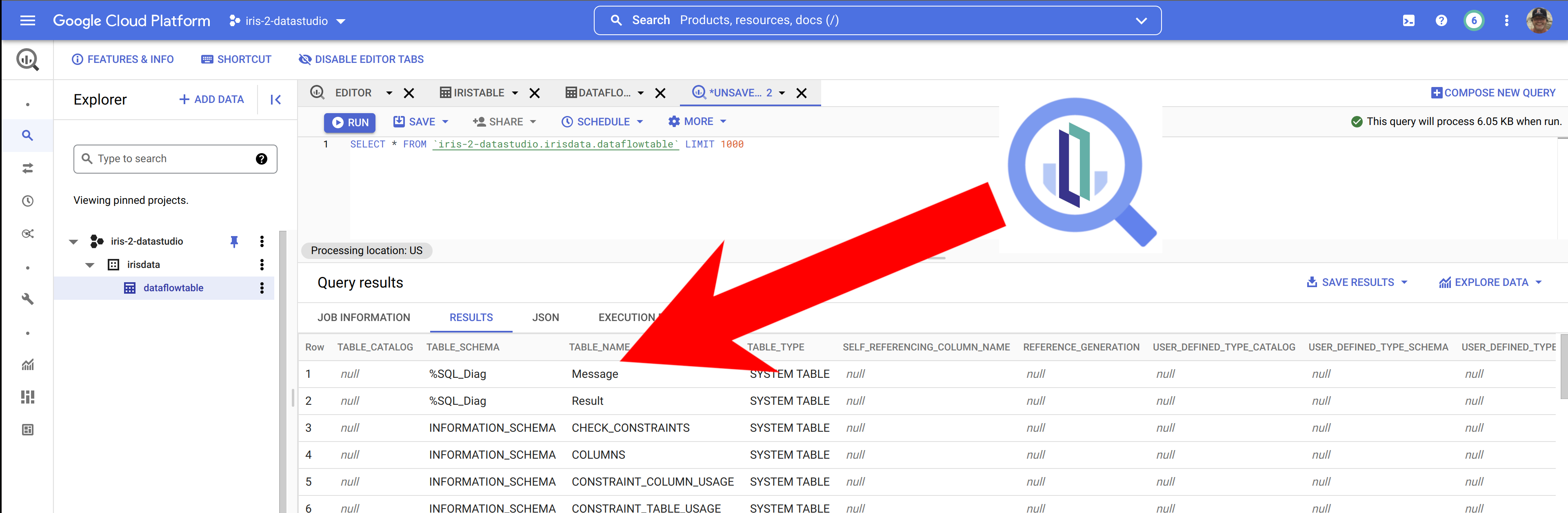
Dada una ubicación del archivo, el siguiente método ObjectScript, CreateSamplePDF(), crea un archivo PDF de muestra y lo guarda en esa ubicación.
Class Demo.PDF
{
ClassMethod CreateSamplePDF(fileloc As%String) As%Status
{
set canvaslib = ##class(%SYS.Python).Import("reportlab.pdfgen.canvas")
set canvas = canvaslib.Canvas(fileloc)
do canvas.drawImage("C:\Sample\isc.png", 150, 600)
do canvas.drawImage("C:\Sample\python.png", 150, 200)
do canvas.setFont("Helvetica-Bold", 24)
do canvas.drawString(25, 450, "InterSystems IRIS & Python. Perfect Together.")
do canvas.save()
}
}La primera línea del método importa el archivo canvas.py del subpaquete pdfgen de ReportLab. La segunda línea del código instancia un objeto Canvas y procede a llamar a sus métodos, de forma muy similar a como llamaría a los métodos de cualquier objeto InterSystems IRIS.
A continuación, podéis llamar al método de la forma habitual:.
do ##class(Demo.PDF).CreateSamplePDF("C:\Sample\hello.pdf")Se genera el siguiente PDF y se guarda en la ubicación especificada:

5.2-Generar código QR utilizando la librería Qrcode de Python
Para generar un código QR, necesitamos instalar la librería Qrcode usando el comando irispip, luego usando el siguiente código podemos generar el Código QR:
.png)
**
5.3-Obtener la geolocalización utilizando la biblioteca Folium de Python
Para obtener los datos geográficos, necesitamos instalar la biblioteca Folium utilizando el comando irispip, luego crear la siguiente función de script del objeto:
Class dc.IrisGeoMap.Folium Extends%SwizzleObject
{
// Function to print Latitude, Longitude and address details ClassMethod GetGeoDetails(addr As%String) [ Language = python ]
{
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent="IrisGeoApp")
try:
location = geolocator.geocode(addr)
print("Location:",location.point)
print("Address:",location.address)
point = location.point
print("Latitude:", point.latitude)
print("Longitude:", point.longitude)
except:
print("Not able to find location")
}
}Conectaos a la Terminal IRIS y ejecutad el siguiente código
do ##class(dc.IrisGeoMap.Folium).GetGeoDetails("Cambridge MA 02142")A continuación se muestra el resultado:


5.4-Generar y marcar localizaciones en un Mapa interactivo utilizando la Biblioteca de Python Folium
Utilizaremos la misma biblioteca Folium de Python para generar y marcar localizaciones en un Mapa interactivo, Abajo la función de script objeto hará lo deseado :
ClassMethod MarkGeoDetails(addr As%String, filepath As%String) As%Status [ Language = python ]
{
import folium
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent="IrisGeoMap")
#split address in order to mark on the map
locs = addr.split(",")
if len(locs) == 0:
print("Please enter address")
elif len(locs) == 1:
location = geolocator.geocode(locs[0])
point = location.point
m = folium.Map(location=[point.latitude,point.longitude], tiles="OpenStreetMap", zoom_start=10)
else:
m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=3)
for loc in locs:
try:
location = geolocator.geocode(loc)
point = location.point
folium.Marker(
location=[point.latitude,point.longitude],
popup=addr,
).add_to(m)
except:
print("Not able to find location : ",loc)
map_html = m._repr_html_()
iframe = m.get_root()._repr_html_()
fullHtml = """
<!DOCTYPE html>
<html>
<head></head>
<body> """
fullHtml = fullHtml + iframe
fullHtml = fullHtml + """
</body>
</html>
"""try:
f = open(filepath, "w")
f.write(fullHtml)
f.close()
except:
print("Not able to write to a file")
}Conectaos a la Terminal IRIS y llamad a la función MarkGeoDetails
Llamaremos a la función MarkGeoDetails() de la clase dc.IrisGeoMap.Folium.
Esta función requiere dos parámetros:
- ubicación/ubicaciones(Podemos pasar varias ubicaciones añadiendo "," entre ellas)
- ruta del archivo HTML
Ejecutemos el siguiente comando para marcar Cambridge MA 02142, NY, Londres, EAU, Jeddah, Lahore y Glasgow en el Mapa y guardémoslo como archivo "irisgeomap_locations.html
do ##class(dc.IrisGeoMap.Folium).MarkGeoDetails("Cambridge MA 02142,NY,London,UAE,Jeddah,Lahore,Glasgow","d:\irisgeomap_locations.html")El código anterior generará el siguiente archivo HTML interactivo:

5.5-Analítica de datos mediante el uso de la biblioteca Pandas de Python
Necesitamos instalar la biblioteca Pandas usando el comando irispip, entonces podemos usar el siguiente código para ver los datos.png)

6-Resumen
InterSystems Embedded Python (IEP) es una potente función que os permite integrar el código Python a la perfección con vuestras aplicaciones de InterSystems. Con IEP, podéis aprovechar las amplias bibliotecas y estructuras disponibles en Python para mejorar la funcionalidad de sus aplicaciones de InterSystems. En este artículo, exploraremos las principales características y ventajas de IEP.
IEP se implementa como un conjunto de bibliotecas que os permiten interactuar con objetos Python y ejecutar código Python desde dentro de las aplicaciones de InterSystems. Esto proporciona una forma sencilla y eficaz de integrar el código Python en vuestras aplicaciones de InterSystems, permitiéndoos realizar análisis de datos, aprendizaje automático, procesamiento del lenguaje natural y otras tareas que pueden resultar difíciles de implementar en InterSystems ObjectScript.
Una de las principales ventajas de utilizar IEP es que proporciona una forma de tender puentes entre los mundos de Python e InterSystems. Esto facilita el uso de los puntos fuertes de ambos lenguajes para crear aplicaciones potentes que combinen lo mejor de ambos mundos.
IEP también proporciona una forma de ampliar la funcionalidad de sus aplicaciones InterSystems aprovechando las capacidades de Python. Esto significa que podéis aprovechar el gran número de bibliotecas y estructura de trabajo disponibles en Python para realizar tareas que pueden resultar difíciles de implementar en InterSystems ObjectScript.
InterSystems Embedded Python proporciona una potente forma de ampliar la funcionalidad de sus aplicaciones de InterSystems aprovechando las capacidades de Python. Al integrar el código Python en sus aplicaciones de InterSystems, podéis aprovechar el gran número de bibliotecas y estructura de trabajo disponibles en Python para realizar tareas complejas que pueden resultar difíciles de implementar en InterSystems ObjectScript.
¡Gracias!

































.png)





){kind=link}