Tuve el mismo problema que contaba Jerry en el siguiente enlace al conectar IRIS con el servidor SQL. Mi conexión ODBC está configurada para autenticarse mediante autenticación nativa de Windows.
¿Cómo lo solucioné yo?
Publicación que incluye la explicación paso a paso sobre las características técnicas o soluciones.
Tuve el mismo problema que contaba Jerry en el siguiente enlace al conectar IRIS con el servidor SQL. Mi conexión ODBC está configurada para autenticarse mediante autenticación nativa de Windows.
¿Cómo lo solucioné yo?
Hola comunidad,
Estamos encantados de compartir un nuevo tutorial en Instruqt:
🧑🏫 RAG usando la búsqueda vectorial de InterSystems IRIS
Este tutorial práctico os guía en la creación de un chatbot de IA con Recuperación Aumentada por Generación (RAG) impulsado por la búsqueda vectorial de InterSystems IRIS. Veréis cómo se puede aprovechar la búsqueda vectorial para ofrecer respuestas actualizadas y precisas, combinando las fortalezas de IRIS con la IA generativa.
.jpg)
✨ ¿Por qué probarlo?

Estoy muy emocionado de continuar con mi serie de artículos "InterSystems para Dummies", y hoy queremos contarles todo sobre una de las funciones más potentes que tenemos para la interoperabilidad.
Aunque ya las hayan probado, planeamos analizar a fondo cómo sacarles el máximo provecho y mejorar aún más nuestra producción.
En esencia, un Record Mapper es una herramienta que permite mapear datos de archivos de texto a mensajes de producción y viceversa. La interfaz del Portal de Administración, por otro lado, permite crear una representación visual de un archivo de texto y un modelo de objeto válido de esos datos para mapearlos a un único objeto de mensaje de producción persistente.
Por lo tanto, si desea importar datos de un archivo CSV a su clase persistente, puede probar con un par de clases entrantes (por FTP o directorio de archivos). ¡Pero no se apresure! Abordaremos cada uno de estos puntos a su debido tiempo.
TIP: Todos los ejemplos y clases descritos en este artículo se pueden descargar desde el siguiente enlace: https://github.com/KurroLopez/iris-recordmap-fordummies.git
Vayamos al grano y especifiquemos nuestro escenario.
Necesitamos importar información de nuestros clientes, incluyendo su nombre, fecha de nacimiento, número de identificación nacional, dirección, ciudad y país.
Abra su portal IRIS y seleccione Interoperabilidad – Crear – Record Maps.

Cree un nuevo Record Maps con el nombre del paquete y la clase.
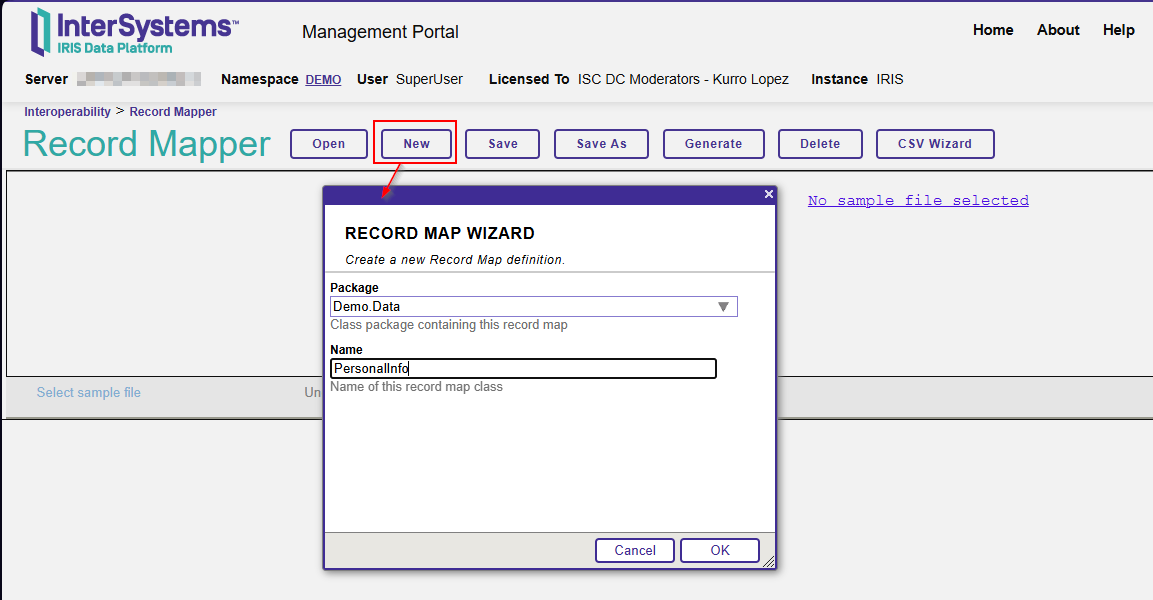
En nuestro ejemplo, el nombre del paquete es Demo.Data, mientras que el nombre de la clase es PersonalInfo.
El primer paso es configurar el archivo CSV. Esto significa determinar el carácter separador, si los campos de cadena tienen comillas dobles, etc.

Si usa el sistema operativo Windows, el terminador de registro común es CRLF (Char(10) Char(12)).
Como mi archivo CSV es estándar, separado por punto y coma (;), debo definir el carácter del separador de campos.
Ahora, voy a declarar los campos del perfil del cliente (nombre, apellidos, fecha de nacimiento, número de identificación nacional, dirección, ciudad y país).

Esta es una definición básica, pero puedes establecer más condiciones con respecto a tu archivo CSV si lo deseas.

Recuerda que, por defecto, un campo %String tiene una longitud máxima de 50 caracteres. Por lo tanto, actualizaré este valor para permitir más caracteres en el campo de dirección (un máximo de 100).
También definiré el formato de fecha usando el formato ISO (aaaa-mm-dd), que corresponde al número 3.
Además, haré obligatorios los campos de nombre, apellido y fecha de nacimiento.

¡Listo! ¡Presionemos el botón "Generar" para crear la clase persistente!

Let's take a look at the generated class:
/// THIS IS GENERATED CODE. DO NOT EDIT.<br/>
/// RECORDMAP: Generated from RecordMap 'Demo.Data.PersonalInfo'
/// on 2025-07-14 at 08:37:00.646 [2025-07-14 08:37:00.646 UTC]
/// by user SuperUser
Class Demo.Data.PersonalInfo.Record Extends (%Persistent, %XML.Adaptor, Ens.Request, EnsLib.RecordMap.Base) [ Inheritance = right, ProcedureBlock ]
{
Parameter INCLUDETOPFIELDS = 1;
Property Name As %String [ Required ];
Property Surname As %String [ Required ];
Property DateOfBirth As %Date(FORMAT = 3) [ Required ];
Property NationalId As %String;
Property Address As %String(MAXLEN = 100);
Property City As %String;
Property Country As %String;
Parameter RECORDMAPGENERATED = 1;
Storage Default
{
<Data name="RecordDefaultData">
<Value name="1">
<Value>%%CLASSNAME</Value>
</Value>
<Value name="2">
<Value>Name</Value>
</Value>
<Value name="3">
<Value>%Source</Value>
</Value>
<Value name="4">
<Value>DateOfBirth</Value>
</Value>
<Value name="5">
<Value>NationalId</Value>
</Value>
<Value name="6">
<Value>Address</Value>
</Value>
<Value name="7">
<Value>City</Value>
</Value>
<Value name="8">
<Value>Country</Value>
</Value>
<Value name="9">
<Value>Surname</Value>
</Value>
</Data>
<DataLocation>^Demo.Data.PersonalInfo.RecordD</DataLocation>
<DefaultData>RecordDefaultData</DefaultData>
<ExtentSize>2000000</ExtentSize>
<IdLocation>^Demo.Data.PersonalInfo.RecordD</IdLocation>
<IndexLocation>^Demo.Data.PersonalInfo.RecordI</IndexLocation>
<StreamLocation>^Demo.Data.PersonalInfo.RecordS</StreamLocation>
<Type>%Storage.Persistent</Type>
}
}
Como puede ver, cada propiedad tiene el nombre de los campos en nuestro archivo CSV.
En este punto, crearemos un archivo CSV con la siguiente estructura para probar nuestro Record Mapper:
Name;Surname;DateOfBirth;NationalId;Address;City;Country Matthew O.;Wellington;1964-31-07;208-36-1552;1485 Stiles Street;Pittsburgh;USA Deena C.;Nixon;1997-03-03;495-26-8850;1868 Mandan Road;Columbia;USA Florence L.;Guyton;2005-04-10;21 069 835 790;Invalidenstrasse 82;Contwig;Germany Maximilian;Hahn;1945-10-17;92 871 402 258;Boxhagener Str. 97;Hamburg;Germany Amelio;Toledo Zavala;1976-06-07;93789292F;Plaza Mayor, 71;Carbajosa de la Sagrada;Spain
Puedes usarlo como prueba ahora.
Haz clic en "Seleccionar archivo de muestra", selecciona la muestra en /irisrun/repo/Samples y elige PersonalInfo-Test.csv.

En este momento podrás observar cómo se importan tus datos:

Justo cuando crees que todo está listo, recibes una nueva especificación de tu jefe:
"Necesitamos los datos para poder cargar el número de teléfono del cliente y almacenar más de uno (fijo, móvil, etc.)".
Uy... Necesito actualizar mi Record Map y agregar un número de teléfono. Sin embargo, debería tener más de uno... ¿Cómo puedo hacerlo?
Nota: Puedes hacerlo directamente en la misma clase. Sin embargo, crearé una nueva para fines explicativos y la guardaré en los ejemplos. De esta manera, puedes revisar y ejecutar el código siguiendo todos los pasos de este artículo.
Bien, es hora de reabrir el Record Map que acabamos de crear.
Agrega el nuevo campo "Phone", pero recuerda indicar que este campo es "Repetido".

Dado que hemos asignado este campo como "Repetido", debemos definir el carácter separador para los datos replicados. Este indicador se encuentra en el mismo lugar donde normalmente especificamos el separador de campo.

¡Perfecto! Carguemos el archivo CSV de ejemplo con los números de teléfono separados por #.

Si echamos un vistazo a la clase persistente que hemos producido, podemos ver que el campo "Phone" es de tipo Lista de %String:
Property Phone As list Of %String(MAXLEN = 20);
Es una muy buena pregunta, querido lector.
Intersystems IRIS nos proporciona dos clases de entrada: EnsLib.RecordMap.Service.FileServiceEnsLib.RecordMap.Service.FTPService
No profundizaré en estas clases porque sería demasiado largo. Sin embargo, podemos revisar sus funciones principales.
En resumen, el servicio monitoriza los procesos en una carpeta definida, captura los archivos almacenados en ese directorio, los carga, los lee línea por línea y envía ese registro al proceso de negocio designado.
Esto ocurre tanto en el servidor como en los directorios FTP.
Vayamos al grano…
Nota: Presentaré mis ejemplos utilizando la clase EnsLib.RecordMap.Service.FileService. Sin embargo, la clase EnsLib.RecordMap.Service.FTPService realiza las mismas operaciones.
Si ha descargado el código de ejemplo, verás que se ha creado una producción con dos componentes:
Una clase de servicio (EnsLib.RecordMap.Service.FileService), que cargará los archivos, y una clase de negocio (Demo.BP.ProcessData), que procesará cada uno de los registros leídos del archivo. En este caso, usaremos este último solo para ver los rastros de comunicación.
Es importante configurar algunos parámetros en la clase del Business Service.

File Path: Es un registro que la clase utiliza para monitorear si hay archivos pendientes de procesamiento. Al colocar un archivo en este directorio, el proceso de carga se activa automáticamente y envía cada registro a la clase definida como Business Process.
File Spec: Es un patrón de archivo para buscar (por defecto, es *, pero podemos definir algunos archivos que deseamos diferenciar de otros procesos). Por ejemplo, podemos tener dos clases de escucha entrantes en el mismo directorio, cada una con una clase RecordMap diferente. Podemos asignar la extensión .pi1 a los archivos que procesará la clase PersonalInfo, mientras que .pi2 marcará los archivos que serán procesados por la clase PersonalInfoPhone.
Archive Path: Es un directorio donde se mueven los archivos después de ser procesados.
Work Path: Es una ruta donde el adaptador debe colocar el archivo de entrada mientras procesa los datos. Esta configuración es útil cuando se usa el mismo nombre de archivo para envíos repetidos. Si no se especifica WorkPath, el adaptador no moverá el archivo durante el procesamiento.
Call Interval: Es la frecuencia (calculada en segundos) de las comprobaciones del adaptador para los archivos de entrada en las ubicaciones especificadas.
RecordMap: Es el nombre de la clase Record Map, que contiene la definición de los datos en el archivo.
Target Config Name: Es el nombre del Proceso de Negocio que maneja los datos almacenados en el archivo.

Subdirectory Levels: Es un espacio donde el proceso busca un nuevo archivo. Por ejemplo, si un proceso añade un archivo cada día (lunes, martes, miércoles, jueves y viernes), buscará en todos los subdirectorios, comenzando por el directorio raíz, siempre que especifiquemos el nivel 1. Por defecto, el nivel 0 significa que solo buscará en el directorio raíz.
Delete From Server: Esta función indica que si no se especifica el directorio de los archivos procesados, el archivo se eliminará del directorio raíz.
File Access Timeout: Es un tiempo definido (calculado en segundos) para acceder al archivo. Si el archivo es de solo lectura o hay algún problema que impida el acceso al directorio, se mostrará un error.
Header Count: Es una característica importante que indica el número de encabezados que se deben ignorar. Por ejemplo, si el archivo tiene un encabezado que especifica los campos que contiene, debe indicar cuántas líneas de encabezado contiene para que se puedan ignorar y solo se puedan leer las líneas de datos.
Como mencioné anteriormente, el proceso de carga se activa cuando se coloca un archivo en el directorio del proceso.
Nota: Las siguientes instrucciones se basan en el código de ejemplo. En la carpeta "samples", encontrará el archivo PersonalInfoPhone-Test.csv. Debe copiar este archivo a la carpeta del proceso para que se procese automáticamente.
NOTA: Si está trabajando con Docker, use el siguiente comando:
docker cp .\PersonalInfoPhone-Test.csv containerId:/opt/irisbuild/process/containerId es el ID de su contenedor, ej: docker cp .\PersonalInfoPhone-Test.csv 66f96b825d43398ba6a1edcb2f02942dc799d09f1b906627e0563b1392a58da1:/opt/irisbuild/process/`

Para cada registro, lanza una llamada al proceso de negocio con todos los datos.

¡Excelente trabajo! En tan solo unos pasos, lograste crear un proceso que puede leer archivos de un directorio y administrar esos datos de forma rápida y sencilla. ¿Qué más podrías pedir a tus procesos de interoperabilidad?
Nadie quiere tener una vida compleja, pero te prometo que te enamorarás de los Complex Record Map .
Los Complex Record Map son precisamente lo que su nombre indica. Se trata de una combinación de varios Record Maps que nos proporciona información más completa y estructurada.
Imaginemos que nuestro jefe nos contacta y nos plantea los siguientes requisitos:
“Necesitamos información del cliente con más números de teléfono, incluyendo códigos de país y prefijos. También necesitamos más direcciones de contacto, incluyendo códigos postales, países y nombres de estados.
Un cliente puede tener un número de teléfono, dos o ninguno”.
Si necesitamos más información sobre números de teléfono y direcciones, como hemos visto anteriormente, incluir esta información en una sola línea sería demasiado complicado. Separemos las diferentes partes que necesitamos:
Para cada sección, crearemos un alias para diferenciar el tipo de información que incluye.
Construyamos cada sección:
Paso 1
Diseña un nuevo Record Maps para la información del cliente (Nombre, Apellidos, Fecha de Nacimiento y Documento Nacional de Identidad) e incluya un identificador para indicar que se trata de la sección USER.

El nombre de la sección debe ser único para los tipos de datos "USER", ya que son responsables de configurar las columnas y posiciones de cada dato. El contenido debería ser similar al siguiente: USER|Matthew O.;Wellington;1964-07-31;208-36-1552 En NEGRITA, el nombre de la sección, en CURSIVA, el contenido.
Paso 2 Crea las secciones PHONE y ADDRESS para los números de teléfono y las direcciones postales.
Recuerda especificar el nombre de la sección y activar la opción Complez Record Map.


Ahora deberíamos tener tres clases:
Paso 3 Completa el Complex Record Map.
Abre la opción "Complex Record Maps":

Lo primero que vemos aquí es una estructura con un encabezado y un pie de página. El encabezado puede ser otro mapa de registros para almacenar información del paquete de datos (por ejemplo, información del departamento del usuario, etc.).
Dado que estas secciones son opcionales, las ignoraremos en nuestro ejemplo.

Establezca el nombre de este registro (por ejemplo, PersonalInfo) y agregue nuevos registros para cada sección.

Si deseamos que uno de los apartados tenga repeticiones, deberemos indicar los valores mínimos y máximos de repetición.

De acuerdo a las especificaciones anteriores, el archivo con la información lucirá así:
USER|Matthew O.;Wellington;1964-07-31;208-36-1552
PHONE|1;305;2089160
PHONE|1;805;9473136
ADDR|1485 Stiles Street;Pittsburgh;15286;PA;USA
Si queremos cargar un archivo, necesitamos un servicio que pueda leer este tipo de archivos, e Intersystems IRIS nos proporciona dos clases de entrada para eso:
EnsLib.RecordMap.Service.ComplexBatchFileServiceEnsLib.RecordMap.Service.ComplexBatchFTPService Como mencioné anteriormente, usaremos la clase EnsLib.RecordMap.Service.ComplexBatchFileService como ejemplo. Sin embargo, el proceso para FTP es idéntico.
Utiliza la misma configuración que el Record Map, excepto por el número de línea del encabezado, porque este tipo de archivo no necesita uno:

Como mencioné anteriormente, el proceso de carga se activa cuando se coloca un archivo en el directorio del proceso.
Nota: Las siguientes instrucciones se basan en el código de ejemplo.
En la carpeta "samples", encontrará el archivo PersonalInfoComplex.txt. Debe copiar este archivo a la carpeta del proceso para que se procese automáticamente.
NOTA: Si trabaja con el ejemplo de Docker, utilice el siguiente comando:
docker cp .\ PersonalInfoComplex.txt containerId:/opt/irisbuild/process/p
containerId es el id de su contenedor, ex: docker cp .\ PersonalInfoComplex.txt 66f96b825d43398ba6a1edcb2f02942dc799d09f1b906627e0563b1392a58da1:/opt/irisbuild/process/
Aquí podemos ver cada fila llamando al Business Service:



Como ya se habrá dado cuenta, los Record Maps son una herramienta potente para importar datos de forma compleja y estructurada. Permiten guardar información en tablas relacionadas o procesar cada dato de forma independiente.
Gracias a esta herramienta, puede crear rápidamente procesos de carga de datos por lotes y almacenarlos sin necesidad de realizar lecturas complejas de datos, separación de campos, validación de tipos de datos, etc.
Espero que este artículo le sea útil.
Nos vemos en el próximo "InterSystems para Dummies".
¡Hola a todos! Tras incorporarme recientemente a InterSystems, me di cuenta de que, a pesar de tener una Community Edition totalmente gratuita y genial, no está muy claro cómo conseguirla. Decidí escribir una guía destacando todas las diferentes formas en que podéis acceder a la Community Edition de InterSystems IRIS:
Trabajar con una instancia en contenedor de la Community Edition es el enfoque recomendado para quienes son nuevos en el desarrollo con InterSystems IRIS, y en mi opinión es el más sencillo. InterSystems IRIS Community Edition se puede encontrar en DockerHub; si tenéis una cuenta SSO de InterSystems, también podéis encontrarla en el InterSystems Container Registry.
En cualquiera de los casos, descargaréis la imagen que necesitéis usando la CLI de Docker:
docker pull intersystems/iris-community:latest-em
// or
docker pull containers.intersystems.com/intersystems/iris-community:latest-emA continuación, tendréis que iniciar el contenedor: para poder interactuar con IRIS desde fuera del contenedor (por ejemplo, para usar el portal de administración) necesitaréis publicar algunos puertos. El siguiente comando ejecutará el contenedor de IRIS Community Edition con los puertos del superserver y del servidor web publicados; tened en cuenta que no podéis tener nada más en ejecución que dependa de los puertos 1972 o 52773.
docker run --name iris -d --publish 1972:1972 --publish 52773:52773 intersystems/iris-community:latest-em🚀 Migración de Datos Clínicos: InterSystems IRIS + Google Cloud HealthcareEn mi laboratorio de integración, he logrado vincular InterSystems IRIS con la API de Google Cloud Healthcare para habilitar un flujo completo de migración y almacenamiento de datos clínicos en formato FHIR R4.🔹 Pasos clave del proceso:1️⃣ Creación de proyecto y habilitación de facturación en Google Cloud.2️⃣ Activación de la API de Cloud Healthcare.3️⃣ Creación de un dataset y un FHIR Store (iris-fhir-store) en us-central1.4️⃣ Configuración de permisos IAM e implementación de una Service Account exclusiva para IRIS.5️⃣
Curso avanzado donde aprenderás a construir soluciones e integraciones con el protocolo HL7-FHIR en InterSystems IRIS for Health™ y HealthShare® Health Connect.
Ahondarás en los fundamentos del estándar FHIR, su arquitectura de instalación, configuración y las diversas opciones de personalización y extensión de servidores FHIR, para almacenar datos en un repositorio FHIR o presentar una fachada FHIR como interfaz para las aplicaciones ya existentes.
Más información e inscripción a través de este enlace: Implementación e integración de soluciones FHIR | InterSystems
Curso online de formación combinada, con parte autoguiada y parte con instructor. Este curso está orientado principalmente para aquellos desarrolladores que deseen iniciarse en los fundamentos del desarrollo en InterSystems IRIS y Health Connect. Los alumnos aprenderán lo necesario para aprovechar el potencial de la plataforma, desde la programación orientada a objetos, acceso y gestión de base de datos mediante SQL y publicación de endpoints basados en API REST.
Más información e inscripciones en el siguiente enlace: Fundamentos de InterSystems IRIS para desarrolladores | InterSystems
En el artículo anterior, Generación de Especificaciones OpenAPI, vimos qué es OpenAPI, por qué es útil para documentar los servicios REST y cómo generar un archivo de especificación en formato .yaml o .json. También exploramos cómo IRIS permite crear automáticamente esta documentación a partir del código existente, siguiendo el enfoque code-first.
Hola Comunidad:
Vamos con el último artículo de cómo grabaros para el bonus de vídeo del Concurso de Artículos.
No voy a entrar en cómo se hacen en edición cosas muy concretas porque varían según el programa que utilicéis. Los atajos de teclado y menús son diferentes, pero el concepto es el mismo. Vais a utilizar un programa para organizar el material grabado, eliminar lo que sobra y darle estructura. Muchos de estos softwares son gratuitos (Capcut, Canva y si no me equivoco DaVinci tuvo una versión gratuita). Yo edito con Adobe Premiere desde hace ya casi diez años (wow me hago viejo) así que si tenéis dudas de ese programa escribidme sin poblemas.
Ahí van algunos consejos concretos:
Hola Comunidad
Como sabréis, el concurso de Artículos Técnicos en Español de este año será en mayo. Voy a hacer una serie de artículos para apoyaros en la creación de los vuestros, dando consejos y trucos.
Como quizás sepáis, entre los bonus o puntuación extra que podéis recibir, está añadir un vídeo tutorial a vuestro artículo. Es posible que no sepáis ni cómo abordar este asunto ¡No hay problema! Os vengo a dar algunos consejos que podéis aplicar no sólo a la creación de estos vídeos, si no a cualquier otro.
Una API REST (Representational State Transfer) es una interfaz que permite que diferentes aplicaciones se comuniquen entre sí a través del protocolo HTTP, utilizando operaciones estándar como GET, POST, PUT y DELETE. Las API REST son ampliamente utilizadas en el desarrollo de software para exponer servicios accesibles por otras aplicaciones, permitiendo la integración entre diferentes sistemas.
Sin embargo, para garantizar que las API sean fáciles de comprender y utilizar, es fundamental contar con una buena documentación. Aquí es donde entra en juego OpenAPI.
Actualizado 02/27/25
Hola Comunidad,
¿Buscáis una forma de integrar a vuestro equipo con InterSystems IRIS® for Health? Descubrid todo el potencial de esta plataforma utilizando estos recursos de aprendizaje de InterSystems. Con una combinación de formación en línea y presencial, podréis apoyar a los distintos roles de vuestra organización y preparar a vuestro equipo para el éxito.
 Una vez que vosotros y vuestro equipo hayáis adquirido suficiente formación y experiencia, ¡obtened la certificación según vuestro rol!
Una vez que vosotros y vuestro equipo hayáis adquirido suficiente formación y experiencia, ¡obtened la certificación según vuestro rol!
💬 Participad en el aprendizaje en la Comunidad de Desarrolladores: chatead con otros desarrolladores, publicad preguntas, leed artículos y manteneos al día con los últimos anuncios. Consultad esta publicación para obtener consejos sobre cómo aprender en la Comunidad de Desarrolladores.
Hola Comunidad,
¿Necesitáis encontrar la orientación más relevante para la incorporación de vuestro equipo de HealthShare Unified Care Record®? Maximizad el conocimiento y el éxito de vuestro equipo explorando esta lista seleccionada de recursos de InterSystems Learning Services, que incluye formación en línea y presencial para una variedad de roles en vuestra organización.on.
En este tutorial, voy a explicar cómo podéis conectar la plataforma de datos IRIS a una base de datos SQL Server utilizando ODBC.
Prerequisitos:
¡Hola, Comunidad!
¿Qué nuevos productos o tecnologías queréis probar en 2025? Estableced vuestros objetivos para 2025 con estos recursos de aprendizaje destacados.
.png)
He estado trabajando en este proceso con algunos compañeros de equipo y pensé que podría ser útil para otros, especialmente si trabajáis con HL7 y Ensemble/HealthConnect/HealthShare y rara vez os aventuráis más allá de la sección de Interoperabilidad.
Primero, me gustaría establecer que este tutorial es una extensión de la documentación ya existente sobre la importación y exportación de datos SQL, que se encuentra aquí: https://docs.intersystems.com/iris20241/csp/docbook/DocBook.UI.Page.cls?KEY=GSQL_impexp#GSQL_impexp_import

Hola Comunidad,
En este artículo voy a enseñar diferentes usos de InterSystems Embedded Python. Vamos a cubrir los siguientes temas:
Empecemos con un resumen

Embedded Python es una característica de la plataforma de datos de InterSystems IRIS que permite a los desarrolladores de Python obtener un acceso completo y directo a los datos y a la funcionalidad de InterSystems IRIS.
InterSystems IRIS incluye con un potente lenguaje de programación incorporado llamado ObjectScript que se interpreta, compila y ejecuta dentro de la plataforma de datos.
Dado que ObjectScript se ejecuta dentro del contexto de InterSystems IRIS, tiene acceso directo a la memoria y a las llamadas a procedimientos de la plataforma de datos.
Embedded Python es una extensión del lenguaje de programación Python que permite la ejecución de código Python dentro del contexto del proceso InterSystems IRIS.
Dado que tanto ObjectScript como Python operan sobre la misma memoria de objetos, puede decirse que los objetos Python no sólo emulan objetos ObjectScript, sino que son objetos ObjectScript.
La coigualdad de estos lenguajes permite que podáis elegir el lenguaje más apropiado para el trabajo, o el lenguaje con el que os sintáis más cómodos para escribir aplicaciones.

Al utilizar Embedded Python, podéis escribir código en tres modalidades diferentes.
En primer lugar, podéis escribir un archivo .py ordinario y llamarlo desde el contexto InterSystems IRIS. En este caso, la plataforma de datos lanzará el proceso de Python y os permitirá importar un módulo llamado IRIS, que asocia automáticamente el proceso de Python al núcleo de IRIS y os proporciona acceso a toda la funcionalidad de ObjectScript desde el contexto de vuestro código Python..png)
En segundo lugar, podéis escribir un código ObjectScript ordinario e instanciar un objeto Python utilizando el paquete %SYS.Python. Este paquete ObjectScript os permite importar módulos y bibliotecas de Python y, a continuación, trabajar con esa base de código utilizando la sintaxis ObjectScript.
El paquete %SYS.Python permite a los desarrolladores de ObjectScript sin ningún conocimiento de Python utilizar el rico ecosistema de bibliotecas Python en su código ObjectScript..png)
En tercer lugar, podéis crear una definición de clase de InterSystems y escribir métodos en Python. Cualquier llamada a ese método lanzará el intérprete de Python. Este método tiene la ventaja de poblar la palabra clave self de ese bloque de código Python con una referencia a la instancia de la clase contenedora. Además, al utilizar Python para escribir métodos de clase en las clases de InterSystems, podéis implementar fácilmente métodos que administren diferentes eventos de entrada de datos en SQL, como la adición de una nueva fila a una tabla.
También permite desarrollar rápidamente procedimientos almacenados personalizados en Python.
.png)
Como podéis ver, Embedded Python os permite elegir el lenguaje de programación más adecuado para el trabajo sin sacrificar el rendimiento.

El intérprete de Python tiene una serie de funciones y tipos incorporados que están siempre disponibles. Se enumeran aquí por orden alfabético.
| Funciones incorporadas | |||
|---|---|---|---|
A
B
C
D
| E
F
G
H
I | L
M
N
O
P
| R
S
T
V
Z
_ |
Uso de las funciones incorporadas de python
Para utilizar una función incorporada de python tenemos que importar "builtins" y después podremos llamar a la función
set builtins = ##class(%SYS.Python).Import("builtins")La función print() de python es en realidad un método del módulo incorporado, por lo que ahora podéis utilizar esta función desde ObjectScript:
USER>do builtins.print("hello world!")
hello world!USER>set list = builtins.list()
USER>zwrite list
list=5@%SYS.Python ; [] ; Del mismo modo, podéis utilizar el método help() para obtener ayuda sobre el objeto lista.
USER>do builtins.help(list)
Help on list object:
class list(object)
| list(iterable=(), /)
|
| Built-in mutable sequence.
|
| If no argument is given, the constructor creates a new empty list.
| The argument must be an iterable if specified.
|
| Methods defined here:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
|
| __delitem__(self, key, /)
| Delete self[key].

Algunos módulos o bibliotecas de Python se instalan de forma predeterminada y ya están disponibles para su uso. Utilizando la función help("module" podemos ver estos módulos: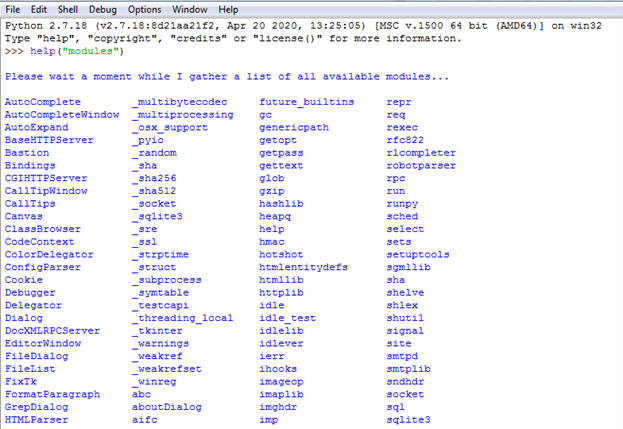

Además de estos módulos en Python existen cientos de módulos o bibliotecas, que se pueden consultar en pypi.org(The Python Package Index (PyPI) es un repositorio de software para el lenguaje de programación Python)
.png)
Si necesitamos algunas otras bibliotecas, entonces necesitamos instalar las bibliotecas usando el comando intersystems irispip
Por ejemplo, Pandas es una biblioteca de análisis de datos de Python. El siguiente comando utiliza el instalador de paquetes irispip para instalar pandas en un sistema Windows:
C:\InterSystems\IRIS\bin>irispip install --target C:\InterSystems\IRIS\mgr\python pandasTened en cuenta que C:\InterSystems será sustituido por el directorio de instalación de Intersystems
5.1-Imprimir PDF utilizando la biblioteca Reportlab de python
Necesitamos instalar la biblioteca Reportlab usando el comando irispip, luego simplemente crear la función objectcript.
Dada una ubicación del archivo, el siguiente método ObjectScript, CreateSamplePDF(), crea un archivo PDF de muestra y lo guarda en esa ubicación.
Class Demo.PDF
{
ClassMethod CreateSamplePDF(fileloc As%String) As%Status
{
set canvaslib = ##class(%SYS.Python).Import("reportlab.pdfgen.canvas")
set canvas = canvaslib.Canvas(fileloc)
do canvas.drawImage("C:\Sample\isc.png", 150, 600)
do canvas.drawImage("C:\Sample\python.png", 150, 200)
do canvas.setFont("Helvetica-Bold", 24)
do canvas.drawString(25, 450, "InterSystems IRIS & Python. Perfect Together.")
do canvas.save()
}
}La primera línea del método importa el archivo canvas.py del subpaquete pdfgen de ReportLab. La segunda línea del código instancia un objeto Canvas y procede a llamar a sus métodos, de forma muy similar a como llamaría a los métodos de cualquier objeto InterSystems IRIS.
A continuación, podéis llamar al método de la forma habitual:.
do ##class(Demo.PDF).CreateSamplePDF("C:\Sample\hello.pdf")Se genera el siguiente PDF y se guarda en la ubicación especificada:

Para generar un código QR, necesitamos instalar la librería Qrcode usando el comando irispip, luego usando el siguiente código podemos generar el Código QR:
.png)
**
Para obtener los datos geográficos, necesitamos instalar la biblioteca Folium utilizando el comando irispip, luego crear la siguiente función de script del objeto:
Class dc.IrisGeoMap.Folium Extends%SwizzleObject
{
// Function to print Latitude, Longitude and address details ClassMethod GetGeoDetails(addr As%String) [ Language = python ]
{
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent="IrisGeoApp")
try:
location = geolocator.geocode(addr)
print("Location:",location.point)
print("Address:",location.address)
point = location.point
print("Latitude:", point.latitude)
print("Longitude:", point.longitude)
except:
print("Not able to find location")
}
}Conectaos a la Terminal IRIS y ejecutad el siguiente código
do ##class(dc.IrisGeoMap.Folium).GetGeoDetails("Cambridge MA 02142")A continuación se muestra el resultado:


Utilizaremos la misma biblioteca Folium de Python para generar y marcar localizaciones en un Mapa interactivo, Abajo la función de script objeto hará lo deseado :
ClassMethod MarkGeoDetails(addr As%String, filepath As%String) As%Status [ Language = python ]
{
import folium
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent="IrisGeoMap")
#split address in order to mark on the map
locs = addr.split(",")
if len(locs) == 0:
print("Please enter address")
elif len(locs) == 1:
location = geolocator.geocode(locs[0])
point = location.point
m = folium.Map(location=[point.latitude,point.longitude], tiles="OpenStreetMap", zoom_start=10)
else:
m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=3)
for loc in locs:
try:
location = geolocator.geocode(loc)
point = location.point
folium.Marker(
location=[point.latitude,point.longitude],
popup=addr,
).add_to(m)
except:
print("Not able to find location : ",loc)
map_html = m._repr_html_()
iframe = m.get_root()._repr_html_()
fullHtml = """
<!DOCTYPE html>
<html>
<head></head>
<body> """
fullHtml = fullHtml + iframe
fullHtml = fullHtml + """
</body>
</html>
"""try:
f = open(filepath, "w")
f.write(fullHtml)
f.close()
except:
print("Not able to write to a file")
}Conectaos a la Terminal IRIS y llamad a la función MarkGeoDetails
Llamaremos a la función MarkGeoDetails() de la clase dc.IrisGeoMap.Folium.
Esta función requiere dos parámetros:
Ejecutemos el siguiente comando para marcar Cambridge MA 02142, NY, Londres, EAU, Jeddah, Lahore y Glasgow en el Mapa y guardémoslo como archivo "irisgeomap_locations.html
do ##class(dc.IrisGeoMap.Folium).MarkGeoDetails("Cambridge MA 02142,NY,London,UAE,Jeddah,Lahore,Glasgow","d:\irisgeomap_locations.html")El código anterior generará el siguiente archivo HTML interactivo:

Necesitamos instalar la biblioteca Pandas usando el comando irispip, entonces podemos usar el siguiente código para ver los datos.png)

InterSystems Embedded Python (IEP) es una potente función que os permite integrar el código Python a la perfección con vuestras aplicaciones de InterSystems. Con IEP, podéis aprovechar las amplias bibliotecas y estructuras disponibles en Python para mejorar la funcionalidad de sus aplicaciones de InterSystems. En este artículo, exploraremos las principales características y ventajas de IEP.
IEP se implementa como un conjunto de bibliotecas que os permiten interactuar con objetos Python y ejecutar código Python desde dentro de las aplicaciones de InterSystems. Esto proporciona una forma sencilla y eficaz de integrar el código Python en vuestras aplicaciones de InterSystems, permitiéndoos realizar análisis de datos, aprendizaje automático, procesamiento del lenguaje natural y otras tareas que pueden resultar difíciles de implementar en InterSystems ObjectScript.
Una de las principales ventajas de utilizar IEP es que proporciona una forma de tender puentes entre los mundos de Python e InterSystems. Esto facilita el uso de los puntos fuertes de ambos lenguajes para crear aplicaciones potentes que combinen lo mejor de ambos mundos.
IEP también proporciona una forma de ampliar la funcionalidad de sus aplicaciones InterSystems aprovechando las capacidades de Python. Esto significa que podéis aprovechar el gran número de bibliotecas y estructura de trabajo disponibles en Python para realizar tareas que pueden resultar difíciles de implementar en InterSystems ObjectScript.
InterSystems Embedded Python proporciona una potente forma de ampliar la funcionalidad de sus aplicaciones de InterSystems aprovechando las capacidades de Python. Al integrar el código Python en sus aplicaciones de InterSystems, podéis aprovechar el gran número de bibliotecas y estructura de trabajo disponibles en Python para realizar tareas complejas que pueden resultar difíciles de implementar en InterSystems ObjectScript.
¡Gracias!
Actualizado 2/27/25
Hola Comunidad,
Podéis liberar todo el potencial de InterSystems IRIS—y ayudar a vuestro equipo a incorporarse—con toda la gama de recursos de aprendizaje de InterSystems que se ofrecen en línea y en persona, para cada función de vuestra organización. Desarrolladores, administradores de sistemas, analistas de datos e integradores pueden ponerse al día rápidamente.
![]() Una vez que vosotros y los miembros de vuestro equipo hayan adquirido suficiente formación y experiencia, podréis obtener la certificación para validar vuestros conocimientos y experiencia en la tecnología de InterSystems.
Una vez que vosotros y los miembros de vuestro equipo hayan adquirido suficiente formación y experiencia, podréis obtener la certificación para validar vuestros conocimientos y experiencia en la tecnología de InterSystems.
Interactuad con otros desarrolladores, publicad preguntas, leed artículos y manteneos al día con los últimos anuncios. Empezad con este post que contiene consejos sobre cómo aprender en la Comunidad de Desarrolladores.
Con estos recursos de aprendizaje, vuestro equipo estará bien equipado para maximizar las capacidades de InterSystems IRIS, impulsando el crecimiento y el éxito de la organización. Si necesitáis ayuda adicional, no dudéis en publicar vuestras preguntas aquí o consultad a vuestro Sales Engineer especializado.
¡Hola a todos!
Llevo muchos años trabajando con Excel y, últimamente, lo he enfocado al tratamiento de bases de datos.
Realmente mi experiencia con Excel ha sido para labores financieras, no tanto analíticas de datos en sí, pero en un proyecto reciente he podido trabajar mucho con SQL y me he interesado un poco por el tema (no soy para nada una experta, ¡aviso!)
Me he preguntado cómo podría unir varios excels en uno para, por ejemplo, entregárselo al Data Análisis utilizando la tecnología InterSystems. He recopilado la información en un pequeño artículo. Espero que sea útil y por supuesto estoy abierta a correcciones.
Vamos a utilizar InterSystems IRIS. Lo que buscaremos es leer los archivos Excel, procesarlos y por último fusionarlos.
Ya estamos en 2024, la version IRIS 2024.1 acaba de salir y todos estamos hablando de ello aquí. Ya tenemos muchos tutoriales sobre búsqueda vectorial y aplicaciones de chats de inteligencia artificial. Hoy quiero proponer algo diferente. Quiero presentar una idea y explorar todos sus límites, y a lo largo del texto plantearé algunas preguntas sobre la capacidad de las herramientas utilizadas, para que luego podamos comprender no solo los resultados de las nuevas funcionalidades, sino también cómo la máquina las procesa.
Ya estamos en 2024, la versión IRIS 2024.1 acaba de salir y todos estamos hablando de ello aquí. Ya tenemos muchos tutoriales sobre búsqueda vectorial y aplicaciones de chats de inteligencia artificial. Hoy quiero proponer algo diferente. Quiero presentar una idea y explorar todos sus límites, y a lo largo del texto plantearé algunas preguntas sobre la capacidad de las herramientas utilizadas, para que luego podamos comprender no solo los resultados de las nuevas funcionalidades, sino también cómo la máquina las procesa.
El almacenamiento en columnas es una de las nuevas ofertas de InterSystems IRIS. A diferencia del almacenamiento tradicional basado en filas, optimiza el procesamiento de consultas al almacenar datos en columnas en lugar de filas, lo que permite un acceso y una recuperación más rápidos de información relevante.
.png)
Se han escrito un par de artículos sobre cuándo se debe utilizar para darle el mayor impulso a un sistema, y cómo crear tablas así usando SQL.
CREATETABLE tabla (columna1 tipo1, columna2 tipo2, columna3 tipo3) WITH STORAGETYPE = COLUMNAR -- ex 1CREATETABLE tabla (columna1 tipo1, columna2 tipo2, columna3 tipo3 WITH STORAGETYPE = COLUMNAR) -- ex 2e incluso las pruebas de rendimiento.
Como todos sabemos, InterSystems IRIS es un DBMS multimodelo y brinda acceso perfecto a los mismos datos mediante acceso relacional y de objetos. Lo primero se trata en otros artículos, pero ¿qué pasa con lo segundo?
Hola Comunidad!
¿Normalmente trabajas con tareas automáticas? Entonces permíteme que comparta contigo un par de consejos ;-)
Imagina que tienes una tarea ejecutándose y te encuentras en la encrucijada de decidir si paras la tarea porque está afectando a otro proceso o la dejas terminar porque puede que le queden solo 5 o 10 minutos.
Aqui tienes una manera para comprobar cuando terminará tu tarea (aproximadamente).
Para este ejemplo he creado una tarea que ejecuta este código:
Recientemente, mientras discutía con mis alumnos el acceso a los datos almacenados en IRIS desde diferentes lenguajes, surgió la pregunta de si era posible iniciar la conexión y obtener datos de la solución Cloud (InterSystems IRIS CloudSQL) desde Microsoft Excel, y no al revés. Teniendo en cuenta las muchas y variadas formas en las que uno puede obtener datos en Excel (importar datos de fuentes externas, conectarse a bases de datos utilizando drivers ODBC, utilizando power queries y web queries, etc.) la opción obvia era probar con el driver ODBC. La única tarea que quedaba era tratar de conectarse a la base de datos en la nube utilizando el driver ODBC.
.png)
La Inteligencia Artificial (IA) está recibiendo mucha atención últimamente porque puede cambiar muchos aspectos de nuestras vidas. Una mayor potencia informática y más datos han ayudado a la IA a hacer cosas asombrosas, como mejorar las pruebas médicas y fabricar coches que se conducen solos. La IA también puede ayudar a las empresas a tomar mejores decisiones y a trabajar de forma más eficiente, por lo que cada vez es más popular y se utiliza más. ¿Cómo se pueden integrar las llamadas a la API OpenAI en una aplicación de interoperabilidad IRIS existente?

En este tutorial, me gustaría hablar sobre las Consultas de Clase (Class Queries). Para ser más precisos, sobre las Consultas basadas en código escrito por el usuario:
Hola comunidad,
El objetivo de este artículo es explicar como crear mensajes entre IRIS y Microsoft Teams.
En mi empresa, tenermos que monitorear mensajes de error, y usamos la clase Ens.Alerts para redireccionar esos mensajes a través de un Business Operation que envía un email.
El problema está en que enviamos esos errores a una cuenta de soporte donde habían muchos emails. Queremos algo específico para un específico equipo.
Por lo que investigamos como hacer que esos mensajes lleguén al equpo de desarrollo directamente y ellos pordrían tener, en tiempo real, una notificación de un error en producción.
En nuestra empresa usamos Microsoft Teams como herramienta corportaiva, por lo que nos preguntamos: ¿Cómo podemos hacer que esos mensajes lleguen al equipo de desarrollo de IRIS?
csp-log-tutorial
Aseguraos de tener git instalado.
Creé una carpeta git dentro del directorio mgr de IRIS. Hice clic derecho en la carpeta git y elegí "Git Bash Here" en el menú contextual.
git clone https://github.com/oliverwilms/csp-log-tutorial.git
Clonad mi repositorio de GitHub csp-log-tutorial si queréis probarlo vosotros mismos.
Mi equipo trabaja con contenedores IRIS que se ejecutan en la plataforma de contenedores Red Hat OpenShift (Kubernetes) en AWS. Implementamos tres pods con el WebGateway que reciben solicitudes a través de un Balanceador de carga de red (Network Load Balancer). Las solicitudes se procesan en una producción de Interoperabilidad que se ejecuta en tres pods de computación. Usamos una producción como banco de mensajes que se ejecuta en pods de datos replicados (mirrored) como un lugar para revisar todos los mensajes procesados por cualquier pod de computación.
Probamos nuestras interfaces usando pods de alimentación para enviar muchos mensajes de solicitud al Balanceador de carga de red. Enviamos 100 000 mensajes y probamos cuánto tiempo llevaría procesar todos los mensajes en el banco de mensajes y registrar las respuestas en los alimentadores. El recuento de mensajes almacenados en el banco de mensajes y las respuestas recibidas por los alimentadores coinciden con el número de mensajes entrantes.
Recientemente nos pidieron que probáramos la tolerancia ante fallos de los pods y de la Zona de Disponibilidad. Borramos pods individuales con o sin fuerza y periodo de gracia. Simulamos un fallo en la zona de disponibilidad al negar todo el tráfico entrante y saliente a una subred (una de las tres zonas de disponibilidad) a través de la consola de AWS mientras los alimentadores envían muchos mensajes de solicitud al Balanceador de carga de red. Ha sido bastante difícil contabilizar todos los mensajes enviados por los alimentadores.
El otro día, mientras un alimentador enviaba 5 000 mensajes, simulamos el fallo de la Zona de disponibilidad. El alimentador recibió 4 933 respuestas. El banco de mensajes almacenó 4 937 mensajes.
Almacenamos access.log y CSP.log en el directorio de datos de los pods de WebGateway. Añadimos esta línea al Dockerfile de nuestra imagen de WebGateway:
RUN sed -i 's|APACHE_LOG_DIR=/var/log/apache2|APACHE_LOG_DIR=/irissys/data/webgateway|g' /etc/apache2/envvars
Configuramos el Nivel de Registro de Eventos (Event Log Level) en Web Gateway en Ev9r.!
Creé los subdirectorios data0, data1 y data2 para nuestros tres pods de webgateway. Copié los archivos CSP.log y access.log de nuestros tres pods de webgateway almacenados en volúmenes persistentes:
oc cp iris-webgateway-0:/irissys/data/webgateway/access.log data0/access.log
oc cp iris-webgateway-1:/irissys/data/webgateway/access.log data1/access.log
oc cp iris-webgateway-2:/irissys/data/webgateway/access.log data2/access.log
oc cp iris-webgateway-0:/irissys/data/webgateway/CSP.log data0/CSP.log
oc cp iris-webgateway-1:/irissys/data/webgateway/CSP.log data1/CSP.log
oc cp iris-webgateway-2:/irissys/data/webgateway/CSP.log data2/CSP.log
Termino con tres subdirectorios, cada uno conteniendo archivos access.log y CSP.log.
Contamos el número de solicitudes procesadas en cualquier pod de webgateway usando este comando:
cat access.log | grep InComingOTW | wc -l
Contamos el número de solicitudes y respuestas registradas en CSP.log usando este comando:
cat CSP.log | grep InComingOTW | wc -l
Normalmente esperamos el doble de líneas en CSP.log en comparación con access.log. A veces encontramos más líneas en CSP.log que el doble esperado de líneas en access.log. Recuerdo haber visto menos líneas de las esperadas en CSP.log en comparación con lo que había en access.log al menos una vez. Sospechamos que esto se debió a una respuesta 500 registrada en access.log, que no se registró en CSP.log, correctamente porque el pod de webgateway se terminó.
Creé las clases persistentes otw.wgw.apache y otw.wgw.csp para importar líneas desde access.log y CSP.log. access.log contiene una línea por solicitud e incluye el estado de la respuesta. CSP.log contiene líneas separadas para solicitudes y respuestas.
Abrid el terminal de IRIS e importad las clases en el directorio src desde el repositorio csp-log-tutorial que habíamos clonado anteriormente:
Set src="C:\InterSystems\IRISHealth\mgr\git\csp-log-tutorial\src"
Do $system.OBJ.LoadDir(src,"ck",,1)
Si no tenéis vuestro propio archivo CSP.log para analizar, podéis importar el que se proporciona en el repositorio csp-log-tutorial:
Set pFile="C:\InterSystems\IRISHealth\mgr\git\csp-log-tutorial\wg2_20230314_CSP.log"
Do ##class(otw.wgw.csp).ImportMessages(pFile,.pLines,.pFilter,1)
pLines y pFilter son parámetros de salida que no son tan importantes en este momento. pImport controla si el Extent se elimina antes de importar los datos.
Después de importar los datos podemos ejecutar consultas SQL como esta:
SELECT count(*) FROM otw_wgw.csp where wgEvent='WebGateway.ProcessRequest'
Si el recuento devuelto es un número impar, indica que hay un desajuste entre las solicitudes y las respuestas.
Podemos ejecutar la siguiente consulta para identificar los nombres de archivo en las solicitudes que no tienen una respuesta coincidente:
select zFilename, count(*) from otw_wgw.csp group by zFilename having count(*) = 1
Tened en cuenta que utilizo el método CalcFilename para establecer la propiedad zFilename antes de guardar una línea importada del archivo CSP.log.
También incluí un archivo access.log de muestra, que podemos importar así: Si no tenéis vuestro propio archivo CSP.log para analizar, podéis importar el que se proporciona en el repositorio csp-log-tutorial:
Set pFile="C:\InterSystems\IRISHealth\mgr\git\csp-log-tutorial\wg2_20230314_access.log"
Do ##class(otw.wgw.apache).ImportMessages(pFile,.pLines,.pFilter,1)
Podemos ejecutar esta consulta para obtener el recuento de mensajes relacionados con este tutorial:
SELECT count(*) FROM otw_wgw.apache where Text like '%tutorial%'
Me gustaría combinar los datos de las tablas apache y csp y posiblemente incluir datos recogidos de los pods de computación.
Creo que puedo utilizar los datos de access.log para determinar cuándo hubo una interrupción en un pod de webgateway.
🐞🐛▶ Existe una herramienta muy útil que nos permite depurar código visualmente usando diferentes colores.

🧩👨💻 Por ejemplo, si tenemos un Business Process, podemos seguir el flujo de ejecución del código escribiendo distintas variaciones de LOGS.

Hola, comunidad!
Después de crear la appIrisApiTester, me di cuenta que podría tener mas potencial, y que con algunos ajustes, podría convertirse en una poderosa herramienta colaborativa.
Me pregunté a mi mismo:
){kind=link}