¡Hola Comunidad!
En este artículo voy a explicar cómo acceder a la información y a las tablas del dashboard (cuadro de mando) del sistema del Portal de Administración mediante el uso de Python Embebido..png)
SQL is un lenguaje estándar para el almacenamiento, manipulación y recuperación de datos en bases de datos relacionales.
¡Hola Comunidad!
En este artículo voy a explicar cómo acceder a la información y a las tablas del dashboard (cuadro de mando) del sistema del Portal de Administración mediante el uso de Python Embebido.
¡Hola Comunidad!
Y para comentar las nuevas funcionalidades y mejoras de la nueva versión, queremos invitaros al webinar: What’s New in InterSystems IRIS 2022.2.
Nota.- el webinar será en inglés.

¡Hola Desarroladores!
IRIS External Table es un proyecto de código abierto de la comunidad de InterSystems, que permite utilizar archivos almacenados en el sistema de archivos local y almacenar objetos en la nube como AWS S3 y tablas SQL. 
Se puede encontrar en GitHub https://github.com/intersystems-community/IRIS-ExternalTable Open Exchange https://openexchange.intersystems.com/package/IRIS-External-Table y está incluido en el administrador de paquetes InterSystems Package Manager (ZPM).
Para instalar External Table desde GitHub, utilice:
git clone https://github.com/antonum/IRIS-ExternalTable.git
iris session iris
USER>set sc = ##class(%SYSTEM.OBJ).LoadDir("<path-to>/IRIS-ExternalTable/src", "ck",,1)
Para instalarlo con el ZPM Package Manager, utilice:
USER>zpm "install external-table"
Crearemos un archivo simple que tiene este aspecto:
a1,b1
a2,b2
Abra su editor favorito y cree el archivo o utilice solo una línea de comandos en Linux/Mac:
echo $'a1,b1\na2,b2' > /tmp/test.txt
Cree una tabla SQL en IRIS para representar este archivo:
create table test (col1 char(10),col2 char(10))
Convierta la tabla para utilizar el almacenamiento externo:
CALL EXT.ConvertToExternal(
'test',
'{
"adapter":"EXT.LocalFile",
"location":"/tmp/test.txt",
"delimiter": ","
}')
Y finalmente, consulte la tabla:
select * from test
Si todo funciona según lo previsto, debería ver el resultado de la siguiente forma:
col1 col2
a1 b1
a2 b2
Ahora regrese al editor, modifique el contenido del archivo y ejecute nuevamente la consulta SQL. ¡¡¡Tarán!!! Está leyendo nuevos valores de su archivo local en SQL.
col1 col2
a1 b1
a2 b99
En https://covid19-lake.s3.amazonaws.com/index.html puede acceder a los datos de la COVID que se actualizan constantemente, estos se almacenan por AWS en el lago de datos públicos.
Intentaremos acceder a una de las fuentes de datos en este lago de datos: s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states
Si tiene instalada la herramienta de línea de comandos para AWS, puede repetir los siguientes pasos. Si no es así, vaya directamente a la parte de SQL. No es necesario que tenga ningún componente específico de AWS instalado en su equipo para continuar con la parte de SQL.
$ aws s3 ls s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/
2020-12-04 17:19:10 510572 us-states.csv
$ aws s3 cp s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv .
download: s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv to ./us-states.csv
$ head us-states.csv
date,state,fips,cases,deaths
2020-01-21,Washington,53,1,0
2020-01-22,Washington,53,1,0
2020-01-23,Washington,53,1,0
2020-01-24,Illinois,17,1,0
2020-01-24,Washington,53,1,0
2020-01-25,California,06,1,0
2020-01-25,Illinois,17,1,0
2020-01-25,Washington,53,1,0
2020-01-26,Arizona,04,1,0
Por lo tanto, tenemos un archivo con una estructura bastante simple y cinco campos delimitados.
Para mostrar esta carpeta S3 como en External Table, primero necesitamos crear una tabla “regular” con la estructura deseada:
-- create external table
create table covid_by_state (
"date" DATE,
"state" VARCHAR(20),
fips INT,
cases INT,
deaths INT
)
Tenga en cuenta que algunos campos de datos como “Date” son palabras reservadas en el SQL de IRIS y deben escribirse entre comillas dobles. Entonces, necesitamos convertir esta tabla “regular” en la tabla “externa”, basada en el bucket AWS S3 y con el tipo CSV.
-- convert table to external storage
call EXT.ConvertToExternal(
'covid_by_state',
'{
"adapter":"EXT.AWSS3",
"location":"s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/",
"type": "csv",
"delimiter": ",",
"skipHeaders": 1
}'
)
Si observa detenidamente, en EXT.ExternalTable los argumentos de los procedimientos son el nombre de la tabla y luego la cadena JSON, además contiene varios parámetros como la ubicación para buscar archivos, el adaptador para utilizarlos, un delimitador, etc. Además, External Table de AWS S3 es compatible con el almacenamiento de Azure BLOB, Google Cloud Buckets y el sistema de archivos local. El repositorio de GitHub contiene referencias para la sintaxis y opciones que son compatibles con todos los formatos.
Y finalmente, consulte la tabla:
-- query the table
select top 10 * from covid_by_state order by "date" desc
[SQL]USER>>select top 10 * from covid_by_state order by "date" desc
2. select top 10 * from covid_by_state order by "date" desc
date state fips cases deaths
2020-12-06 Alabama 01 269877 3889
2020-12-06 Alaska 02 36847 136
2020-12-06 Arizona 04 364276 6950
2020-12-06 Arkansas 05 170924 2660
2020-12-06 California 06 1371940 19937
2020-12-06 Colorado 08 262460 3437
2020-12-06 Connecticut 09 127715 5146
2020-12-06 Delaware 10 39912 793
2020-12-06 District of Columbia 11 23136 697
2020-12-06 Florida 12 1058066 19176
Es comprensible que se necesite más tiempo para consultar los datos de la tabla remota, que para consultar la tabla “nativa de IRIS” o la tabla basada en el global, pero esta se almacena y actualiza completamente en la nube, y en segundo plano se extrae a IRIS.
Exploremos un par de funciones adicionales de External Table.
La carpeta de nuestro ejemplo, que se encuentra en el bucket, contiene solo un archivo. Lo más común es que tenga varios archivos de la misma estructura, donde el nombre del archivo identifique tanto al registro de la hora como al identificador de algún otro atributo que queramos utilizar en nuestras consultas.
El campo %PATH se agrega automáticamente a cada tabla externa y contiene la ruta completa hacia el archivo de donde se recuperó la fila.
select top 5 %PATH,* from covid_by_state
%PATH date state fips cases deaths
s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv 2020-01-21 Washington 53 1 0
s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv 2020-01-22 Washington 53 1 0
s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv 2020-01-23 Washington 53 1 0
s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv 2020-01-24 Illinois 17 1 0
s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv 2020-01-24 Washington 53 1 0
Puede utilizar el campo %PATH en sus consultas SQL como cualquier otro campo.
Si su tarea es cargar datos de S3 en una tabla IRIS, puede utilizar External Table como una herramienta ETL. Simplemente haga lo siguiente:
INSERT INTO internal_table SELECT * FROM external_table
En nuestro caso, si queremos copiar los datos COVID de S3 a la tabla local:
--create local table
create table covid_by_state_local (
"date" DATE,
"state" VARCHAR(100),
fips INT,
cases INT,
deaths INT
)
--ETL from External to Local table
INSERT INTO covid_by_state_local SELECT TO_DATE("date",'YYYY-MM-DD'),state,fips,cases,deaths FROM covid_by_state
External Table es una tabla SQL. Se puede unir con otras tablas, utilizarse en subconsultas y sistemas de archivos tipo UNION. Incluso puede combinar la tabla “Regular” de IRIS y dos o más tablas externas que provengan de diferentes fuentes en la misma consulta SQL.
Intente crear una tabla regular, por ejemplo, haga coincidir los nombres de los estados con sus códigos como en el caso de Washington y WA. Y únalos con nuestra tabla basada en S3.
create table state_codes (name varchar(100), code char(2))
insert into state_codes values ('Washington','WA')
insert into state_codes values ('Illinois','IL')
select top 10 "date", state, code, cases from covid_by_state join state_codes on state=name
Cambie “join” por “left join” para incluir aquellas filas donde el código del estado no esté definido. Como puede ver, el resultado es una combinación de datos provenientes de S3 y su tabla nativa de IRIS.
El lago de datos Covid en AWS es público. Cualquier persona puede leer los datos que provengan de esta fuente sin la necesidad de tener alguna autenticación o autorización. En la vida real seguramente quiere acceder a sus datos de una forma segura, donde se evite que extraños echen un vistazo a sus archivos. Los detalles completos sobre AWS Identity y Access Management (IAM) están fuera del alcance de este artículo. Pero lo mínimo que debe saber es que necesita por lo menos la clave de acceso a la cuenta y la información confidencial de AWS para acceder a los datos privados de su cuenta. https:
AWS utiliza la autenticación de claves/información confidencial de la cuenta para firmar las solicitudes. https://docs.aws.amazon.com/general/latest/gr/aws-sec-cred-types.html#access-keys-and-secret-access-keys
Si está ejecutando IRIS External Table en una instancia de EC2, la forma recomendada de lidiar con la autenticación es utilizando las funciones que se encuentran en la instancia de EC2 https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/iam-roles-for-amazon-ec2.html. De este modo, IRIS External Table podría utilizar los permisos de esa función. No se requiere ninguna configuración adicional.
En una instancia local o que no sea de EC2 es necesario especificar AWS_ACCESS_KEY_ID y AWS_SECRET_ACCESS_KEY, ya sea con la ayuda de variables de entorno o mediante la instalación y configuración del cliente CLI de AWS.
export AWS_ACCESS_KEY_ID=AKIAEXAMPLEKEY
export AWS_SECRET_ACCESS_KEY=111222333abcdefghigklmnopqrst
Asegúrese de que la variable de entorno sea visible dentro del proceso de IRIS. Puede verificarlo al ejecutar:
USER>write $system.Util.GetEnviron("AWS_ACCESS_KEY_ID")
Esto debería emitir el valor de la clave.
O instale el CLI de AWS, mediante instrucciones que se encuentran aquí: https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2-linux.html y ejecutar:
aws configure
Entonces External Table podrá leer las credenciales desde los archivos de configuración para el CLI de AWS. Posiblemente su shell interactivo y el proceso de IRIS estén ejecutándose en cuentas diferentes, asegúrese de ejecutar aws configure con la misma cuenta que su proceso de IRIS.
Acabo de redactar un ejemplo rápido para ayudar a un colega a cargar datos en IRIS desde R usando RJDBC y pensé que sería útil compartirlo aquí para futuras consultas.
Fue bastante sencillo, aparte de que a IRIS no le gusta el uso de puntos "." en los nombres de las columnas; la solución alternativa es simplemente renombrar las columnas. Alguien con más conocimientos que yo en R seguramente pueda ofrecer un enfoque más amplio ![]()
# Es necesario un valor válido para el JAVA_HOME antes de cargar la librería (RJDBC) Sys.setenv(JAVA_HOME="C:\\Java\\jdk-8.0.322.6-hotspot\\jre") library(RJDBC) library(dplyr) # Conexión a IRIS – se requiere la ruta a la librería JAR de InterSystems JDBC JAR de tu instalación drv <- JDBC("com.intersystems.jdbc.IRISDriver", "C:\\InterSystems\\IRIS\\dev\\java\\lib\\1.8\\intersystems-jdbc-3.3.0.jar","\"") conn <- dbConnect(drv, "jdbc:IRIS://localhost:1972/USER", "IRIS Username", "IRIS Password") dbListTables(conn) # Para mayor confusión, cargar el dataset de IRIS:) data(iris) # A IRIS no le gustan los puntos "." en el nombre de las columnas, así que los renombramos. (Probablemente se pueda codificar de una forma más genérica, pero no soy muy bueno con R.) iris <- iris %>% rename(sepal_length = Sepal.Length, sepal_width = Sepal.Width, petal_length = Petal.Length, petal_width = Petal.Width) # dbWriteTable/dbGetQuery/dbReadTable funcionan dbWriteTable(conn, "iris", iris, overwrite = TRUE) dbGetQuery(conn, "select count(*) from iris") d <- dbReadTable(conn, "iris")
hi, my apologises for my english and my level . //al final en castellano
first i am having problem executing in terminal with $SYSTEM.SQL.Shell() when i work with the << entering multiline statement mode >>
i ve tried this ...
Tengo una clase %Persistent con propiedades que son de %SerialObject. Quiero añadir un índice a una propiedad de la clase %SerialObject.
¿Es posible?
Recientemente surgió un patrón interesante en torno a los índices únicos (en una discusión interna re: isc.rest) y me gustaría destacarlo para la Comunidad.
Como caso de uso motivador: supón que tienes una clase que representa un árbol, donde cada nodo también tiene un nombre, y queremos que los nodos sean únicos por nombre y nodo principal. Queremos que cada nodo raíz también tenga un nombre único. Una implementación natural sería:
Publicación Original por: Anton Umnikov
Arquitecto Senior de soluciones en la nube en InterSystems
AWS CSAA, GCP CACE
AWS Glue es un proceso ETL (extraer, transformar y cargar) completamente gestionado, que hace sencillo y rentable clasificar los datos, limpiarlos, enriquecerlos y moverlos de forma fiable entre diferentes almacenes de datos.
En el caso de InterSystems IRIS, AWS Glue permite mover grandes cantidades de datos a IRIS desde fuentes de datos tanto en la nube como en las propias instalaciones (on-premise). Las fuentes de datos potenciales incluyen, pero no se limitan a, bases de datos on-prem, archivos CSV, JSON, Parquet y Avro que residen en buckets S3, bases de datos nativas en la nube como AWS Redshift y Aurora, y muchas otras.

Este artículo asume que tienes un conocimiento básico de AWS Glue, al menos en el nivel para completar los Tutoriales de introducción a AWS Glue . Nos centraremos en los aspectos técnicos de la configuración de los trabajos (Jobs) en AWS Glue para utilizar InterSystems IRIS como Datos Objetivo, o en otros términos, "receptor de datos".

Imagen de https://docs.aws.amazon.com/glue/latest/dg/components-key-concepts.html
Los Trabajos en AWS Glue se ejecutan "sin servidor". Todos los recursos necesarios para realizar el trabajo son suministrados de forma dinámica por AWS solo durante el tiempo en que el trabajo se ejecuta realmente; y se destruyen en el momento en que el trabajo se completa. Por eso, en lugar de provisionar, gestionar e incurrir en costes continuos por la infraestructura necesaria, se te factura solo por el tiempo en que el trabajo realmente se ejecuta y puedes dedicar tus esfuerzos a escribir el código del Trabajo. Durante el tiempo de "inactividad" no se consumen recursos, salvo los buckets S3, que almacenan el código del Trabajo y la configuración.
 Aunque hay varias opciones disponibles, normalmente los Trabajos en Glue se ejecutan con un suministro dinámico en Apache Spark y se escriben en código PySpark. El Trabajo en Glue contiene la sección _"Extraer"_ (donde los datos se extraen de las fuentes de datos), una serie de _"Transformaciones"_ (construidas utilizando la API de Glue) y finalmente la parte _"Cargar"_ o _"receptor"_, en la que después de la transformación final los datos se escriben en el sistema objetivo.
Aunque hay varias opciones disponibles, normalmente los Trabajos en Glue se ejecutan con un suministro dinámico en Apache Spark y se escriben en código PySpark. El Trabajo en Glue contiene la sección _"Extraer"_ (donde los datos se extraen de las fuentes de datos), una serie de _"Transformaciones"_ (construidas utilizando la API de Glue) y finalmente la parte _"Cargar"_ o _"receptor"_, en la que después de la transformación final los datos se escriben en el sistema objetivo.
Para permitir que AWS Glue interactúe con IRIS necesitamos asegurar lo siguiente:
Examinemos cada uno de los pasos necesarios.
En la consola AWS, selecciona AWS Glue->Connections->Add Connection

Introduce el nombre de tu conexión y selecciona "JDBC" como Tipo de Conexión.

En la URL de JDBC introduce la cadena de conexión JDBC para tu instancia de IRIS, el nombre de usuario y la contraseña.
El siguiente paso es crucial, necesitas asegurarte de que Glue coloca sus endpoints en el mismo VPC que tu instancia de IRIS. Selecciona la VPC y la Subred de tu instancia de IRIS. Cualquier grupo de seguridad con una regla de entrada de autorreferencias para todos los puertos TCP se ejecutaría aquí. Por ejemplo, el grupo de seguridad de tu instancia de IRIS.
Si aún no lo has hecho, carga el archivo JAR del controlador JDBC de IRIS intersystems-jdbc-3.0.0.jar en el bucket S3. En este ejemplo, estoy usando el bucket s3://irisdistr. Sería distinto para tu cuenta.
Necesitas crear un rol de IAM para tu Trabajo en Glue, que pueda acceder a ese archivo, junto con otros buckets S3 que Glue utilizaría para almacenar scripts, registros, etc.
Asegúrate de que tiene acceso de lectura al bucket de tu controlador JDBC. En este caso, concedemos a esta función (GlueJobRole) acceso de solo lectura (ReadOnly) a todos los buckets, junto con el AWSGlueServiceRole predefinido. Puedes elegir limitar aún más los permisos de este rol.

Crear un nuevo Trabajo en Glue. Selecciona el rol de IAM, que creamos en el paso anterior. Deja todo lo demás de forma predeterminada.
En "Security configuration, script libraries, y job parameters (optional)" establece en "Dependent jars path" la ubicación del intersystems-jdbc-3.0.0.jar en el bucket S3.

Para la fuente: utiliza una de tus fuentes de datos preexistentes. Si seguiste los tutoriales mencionados más arriba, ya tendrás al menos una.
Utiliza la opción "Create tables in your data target" y selecciona la conexión IRIS que has creado en el paso anterior. Deja todo lo demás de forma predeterminada.
Si nos has seguido hasta ahora, deberías llegar a una pantalla similar a esta:

¡Ya queda poco! Solo necesitamos hacer un sencillo cambio en el script para cargar datos en IRIS.
El script que Glue generó para nosotros utiliza AWS Glue Dynamic Frame, extensión propietaria de AWS para Spark. Aunque ofrece algunos beneficios para los trabajos de ETL, también garantiza que no puedes escribir datos en ninguna base de datos para la que AWS no haya administrado la oferta de servicios.
Buenas noticias- en el momento de escribir los datos en la base de datos ya no son necesarios todos los beneficios de Dynamic Dataframe, como no aplicación de esquema para los datos "sucios" (en el momento de escribir los datos se supone que están "limpios") y podemos convertir fácilmente Dynamic Dataframe a un Dataframe nativo en Spark que no está limitado a los objetivos administrados por AWS y puede trabajar con IRIS.
Así que la línea que necesitamos cambiar es la línea 40 de la imagen más arriba. Un último consejo.
Este es el cambio que necesitamos hacer:
#datasink4 = glueContext.write_dynamic_frame.from_jdbc_conf(frame = dropnullfields3, catalog_connection = "IRIS1", connection_options = {"dbtable": "elb_logs", "database": "USER"}, transformation_ctx = "datasink4")
dropnullfields3.toDF().write \
.format("jdbc") \
.option("url", "jdbc:IRIS://172.30.0.196:51773/USER/") \
.option("dbtable", "orders") \
.option("user", irisUsername) \
.option("password", irisPassword) \
.option("isolationlevel","NONE") \
.save()Donde irisUsername e irisPassword son el nombre de usuario y las contraseñas para tu conexión JDBC en IRIS.
Nota: almacenar las contraseñas en el código fuente NO es conveniente. Te animamos a utilizar herramientas como AWS Secrets Manager para ello, pero entrar en este nivel de detalles de seguridad está más allá del alcance de este artículo. Este es un buen artículo sobre el uso de AWS Secrets Manager en AWS Glue.
Ahora pulsa el botón "Run Job", siéntate y relájate mientras AWS Glue efectúa el proceso ETL por ti.
Bueno... lo más probable es que cometas algunos errores al principio... Todos sabemos cómo funciona. Una errata por aquí, un puerto equivocado en el grupo de seguridad por allí... AWS Glue utiliza CloudWhatch para almacenar todos los registros de ejecución y de errores. Busca grupos de registro en: /aws-glue/jobs/error y _ /aws-glue/jobs/output_, para identificar lo que salió mal.
¡Disfruta de la programación de los procesos ETL en la nube!
Digamos que tengo una clase persistente en IRIS con una propiedad opcional EmailOptIn:
Class Person Extends %Persistent
{
Property Name As %String;
Property EmailOptIn As %Boolean;
}
Más tarde me doy cuenta de que estoy haciendo muchas comprobaciones nulas en esta propiedad donde no debería ser necesario. La solución es hacer de esto una propiedad requerida:
Class Person Extends %Persistent
{
Property Name As %String;
Property EmailOptIn As %Boolean [ Required ];
}
Cuando hago este cambio, tendré que actualizar todos los datos existentes para establecer un valor predeterminado razonable donde sea nulo. De lo contrario, estoy en un mal estado donde la actualización del nombre de una persona fallará si su EmailOptIn es nulo. Podría esperar arreglar esto en SQL de la siguiente manera:
&sql(update Person set EmailOptIn = 0 where EmailOptIn is null)
Sin embargo, ejecutar esta consulta me dejará sin filas afectadas. También puedo usar una declaración SELECT para verificar que la condición WHERE no coincida con filas. Interpreto esto como SQL, suponiendo que ninguna de las entradas sea nula, ya que se requiere la propiedad. La solución es un poco intuitiva. Aunque no existe ningún índice, el uso de la palabra clave %NOINDEX en la condición obliga a la actualización a comprobar si hay entradas nulas.
&sql(update Person set EmailOptIn = 0 where %NOINDEX EmailOptIn is null)
Este caso extremo me hizo atascarme recientemente. Espero que este artículo pueda ahorrar algo de tiempo a otros desarrolladores.
¡Hola a tod@s!
Hoy os traigo un artículo de Kyle Baxter sobre búsquedas de texto libre que vale la pena guardar como referencia :)
¿Os gustaría buscar de forma eficiente campos de texto libres almacenados en vuestra aplicación? ¿Lo habéis intentado alguna vez pero no habéis encontrado una manera que os ofrezca un buen rendimiento? Hay un truco especial que resuelve el problema :)
Como es habitual, si preferís la versión TL;DR (Demasiado largo, no lo he leído), podéis ir directamente al final del artículo, pero preferiríamos que leyeseis el artículo entero para evitar herir sentimientos.
¡Hola desarrolladores!
A veces necesitamos insertar o referir los datos de clases directamente en globals.
Y quizá muchos de vosotros esperáis que la estructura de datos de una global con registros sea:
^Sample.Person(Id)=$listbuild("",col1,col2,...,coln).Este artículo es un aviso de que esto no siempre es verdad, así que no se debe dar por supuesto!
¡Hola desarrolladores!
En mis artículos anteriores, una de las cosas más interesantes de FHIR que mencioné es el amplio rango de posibilidades que tenemos y no solo para crear algo, sino las maneras de conseguir este objetivo.
En mis artículos estoy compartiendo mi experiencia trabajando con FHIR. Solo usaba los Recursos FHIR aportados por la API. Recuperando y actualizando los Recursos FHIR en el servidor FHIR usando javascript con la ayuda de fhir.js
Encontrar errores en tu código o examinar un comportamiento inesperado es el principal objetivo de la depuración.
Trataré de actualizar las herramientas tradicionales aparte de las ayudas que tienen Studio, VScode, Serenji... Las herramientas básicas que han estado ahí antes de que tu EDI preferido lo utilizara en segundo plano.
En este artículo, explicaré el uso de las tablas %SQL_Diag.Result y %SQL_Diag.Message junto con la nueva funcionalidad LOAD DATA.
Se recomienda revisar primero la documentación LOAD DATA.
Después del éxito de una operación, LOAD DATA inserta un registro en la tabla %SQL_Diag.Result y los detalles se insertan en la tabla %SQL_Diag.Message
A continuación se muestra el comando básico cuando la tabla ya está creada y el archivo de origen no contiene una fila de encabezado.
LOAD DATA FROM FILE 'C://TEMP/mydata.txt' INTO MyTable
El nombre del archivo debe incluir un sufijo .txt o .csv (valores separados por comas) y tanto el origen como el destino tienen la misma secuencia de columnas de datos.
Gracias a @Yuri Marx hemos visto un buen ejemplo de Migración de Bases de datos de Postgres a IRIS.
Mi problema personal es el uso de DBeaver como una herramienta de migración.
En especial, como una de las fortalezas de IRIS (y también Caché) es la disponibilidad de los SQLgateways que permiten el acceso a cualquier base de datos externa, siempre y cuando se puedan acceder usando ODBC/JDBC. Así que he ampliado el paquete para demostrarlo.
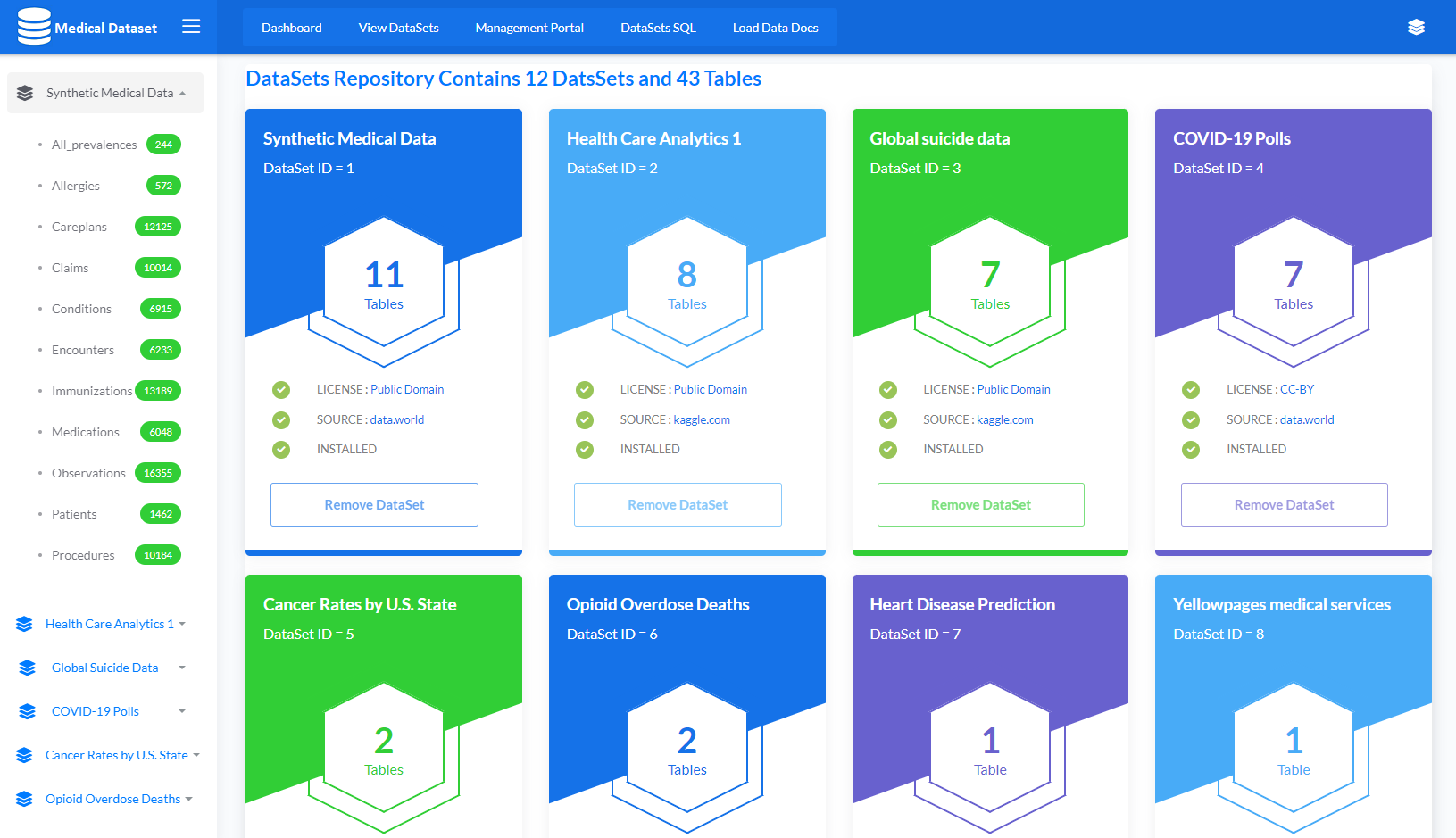
He desarrollado una aplicación para importar de forma dinámica 12 conjuntos de datos junto con 43 tablas usando el comando LOAD DATA, que carga los datos de una fuente a una tabla SQL de IRIS.
Lista de los conjuntos de datos
Se recomienda leer la documentación relacionada LOAD DATA (SQL).
Utiliza el siguiente comando para importar un conjunto de datos en particular al introducir su ID o utiliza 999 para importar todos los conjuntos de datos
do ##class(dc.data.medical.utility).ImportDS(1)
A continuación se muestra el script principal para crear la tabla de forma dinámica y cargar los datos mediante la función LOAD DATA. Ten en cuenta que la tabla se crea de forma dinámica
//Get file name
SET filename=tRS.Get("Name")
//Remove .csv from the file name
SET tableName=$REPLACE("dc_data_"_ds_"."_tRS.Get("ItemName"),".csv","")
//Get columns based on the header row of csv file
Do ##class(dc.data.medical.utility).GetColTypes(filename,.coltype)
//Dynamically create table based on tablename and column types
SET qry = "CREATE TABLE "_tableName_" ("_coltype_")"
SET rset = ##class(%SQL.Statement).%ExecDirect(,qry)
//Check if table created successfully
IF rset.%SQLCODE
{
WRITE "ERROR : ",rset.%Message,!
}
ELSE
{
//Dynamically construct LOAD DATA statement
SET qry = "LOAD DATA FROM FILE '"_filename_"' INTO "_tableName_ " "_"USING {""from"":{""file"":{""header"":""1""}}}"
SET rset = ##class(%SQL.Statement).%ExecDirect(,qry)
// Check result set sqlcode, In case of error write resultset message
IF rset.%SQLCODE
{
WRITE "ERROR Table : " _tableName_" IMPORT FAILED: ",rset.%Message,!
}
ELSE
{
WRITE "SUCCESS table : " _tableName_" created and "_rset.%ROWCOUNT_" Rows Imported Successfully",!
}
}Utiliza el siguiente comando para eliminar un conjunto de datos en particular al introducir su ID o utiliza 999 para eliminar todos los conjuntos de datos
do ##class(dc.data.medical.utility).RemoveDS(1)
A continuación se muestra el script principal para eliminar la tabla de forma dinámica
//Get file name
SET filename=tRS.Get("Name")
//Remove .csv from file name
SET tableName=$REPLACE("dc_data_"_ds_"."_tRS.Get("ItemName"),".csv","")
//Drop table
SET qry = "DROP TABLE "_tableName
SET rset = ##class(%SQL.Statement).%ExecDirect(,qry)
//Check if table deleted successfully
IF rset.%SQLCODE
{
WRITE "ERROR : ",rset.%Message,!
}
ELSE
{
WRITE "Table "_tableName_" deleted successfully",!
}
Si el conjunto de datos no está instalado, el botón "Install DataSet" estará visible y si el conjunto de datos está instalado, el botón "Remove Dataset" estará visible.
Solo hay que hacer clic en el botón adecuado para instalar o eliminar cualquier conjunto de datos.png)
Ve a la página View Datasets http://localhost:52773/csp/datasets/datasets.csp
Selecciona un conjunto de datos específico y después una tabla de la lista. Haz clic en el botón Excel, CSV o PDF para exportar los datos.
.png)
Espero que os resulte útil.
Una de nuestras apps utiliza una consulta de clase para un informe ZEN y funciona perfectamente en ese informe, produciendo los resultados esperados. Hemos migrado a InterSystems Reports y nos hemos dado cuenta de que, para un informe que utiliza la misma consulta de clase, aparecen en la parte de abajo más de 100 filas extra con los mismos valores en las columnas.
Descartamos InterSystems Reports como fuente del problema reproduciendo el problema de "filas extra" con una hoja de cálculo de Excel que llama a la misma consulta de clase utilizando un procedimiento almacenado.
¿Cuál era el problema? Cuando llamábamos al procedimiento almacenado desde el antiguo ZEN Report o desde la función SQL Query en el Portal de Administración, no veíamos estas filas adicionales.
¡Hola comunidad!
En esta publicación voy a explicar cómo mostrar datos en internet usando Python embebido, Marco web Python Flask y jQuery DataTable.
Mostraré los procesos desde la tabla %SYS.ProcessQuery.
<table id="myTable" class="table table-bordered table-striped">
</table>¡Hola desarrolladores!
Como probablemente sabéis, en IRIS 2021 los nombres de los globals son aleatorios.
Y si creas clases de IRIS con DDL y quieres estar seguro de qué global se creó, seguramente te gustaría darle un nombre.
De hecho, se puede hacer.
Usa WITH %CLASSPARAMETER DEFAULTGLOBAL='^GLobalName' en la Tabla CREATE para que funcione. Documentación. Mirad este ejemplo:
Buenas tardes,
Hace ya tiempo que tengo esta duda y no sé si alguno sabrá la respuesta. Cuando realizo un insert por SQL desde una aplicación externa en los campos de tipo %String si están vacíos me graba el caracter $c(0) en el global.
Revisando la documentación he visto que existe una propiedad para las clases que extienden de %XML.Adapter que si sobreescribes el parametro XMLIGNORENULL = 1 puedes hacer que guarde cadenas vacías en lugar de nulos.
He intentado hacer que mis clases extiendan de %XML.Adapter pero si sobreescribo la propiedad sigue haciendo lo mismo, ejemplo:
Benjamin De Boe escribió este magnífico artículo sobre las Consultas universales en caché, pero ¿qué es una Consulta universal en caché (UCQ) y por qué deberían interesarme, si yo escribo en el antiguo y válido SQL embebido? En Caché y Ensemble, las consultas en caché o cacheadas se generaban para resolver xDBC y SQL dinámico. Ahora, en InterSystems IRIS, SQL embebido se ha sido actualizado para utilizar las consultas cacheadas (Cached Queries), de ahí que se añadiera la palabra "universal" en el nombre. Actualmente, cualquier SQL que se ejecute en IRIS lo hará desde una clase UCQ.
Necesito iterar múltiples veces el mismo ResultSet. ¿Cómo puedo volver al primer resultado?
Si defines una tabla/clase persistente, el compilador de clases genera una definición de almacenamiento adecuada. Otra opción es definir un mapeo SQL para un almacenamiento global que ya existe. Esto ya se explicó estupendamente en otra serie de artículos: El arte del mapeo de globales para Clases 1 de 3
Después de definir el diagrama de almacenamiento, el compilador de la clase lo podrá ampliar, pero los parámetros fundamentales de almacenamiento no cambiarán.
Esto no significa que no puedas cambiarlo manualmente.
Mi artículo El mapa de bits adoptado incluye un caso como este. Y en combinación con algunas Condiciones WHERE estáticas, como se describió anteriormente, permite que esté disponible también para SQL.
La definición habitual de tus globals de almacenamiento se parecerá a este ejemplo:
Ahora cambiaremos esta definición por una dinámica
y añadimos algo de comodidad
Para acceder a los objetos, dirigimos nuestro almacenamiento y lo llenamos
y en SQL:
Funciona con PPG (^||Person)
mediante el namespace (^|"USER"|Person)
también corresponde al subíndice que se utilizó en El mapa de bits adoptado con otra variante de ClassMethod SetStorage()
Para acceso a objetos (sin SQL), funciona incluso para variables locales.
No es el uso deseado, pero demuestra la flexibilidad de esta función.
Pero ten cuidado. NO funcionará con sharding. Pero eso no es una sorpresa.
¡Hola desarrolladores!
Os traemos la primera ponencia del Virtual Summit 2021, ya disponible en el Canal de YouTube de la Comunidad de Desarrolladores en inglés.
El idioma del vídeo es el inglés y podéis activar los subtítulos en inglés si os resulta más fácil entender el vídeo leyendo el texto. Solo tenéis que hacer clic en el icono de subtítulos abajo:

¡Hola amigos!
A veces necesitamos importar datos a InterSystems IRIS desde archivos de tipo CSV. Esto puede hacerse, por ejemplo, mediante la herramienta csvgen, que genera una clase e importa todos los datos a ella.
Pero, ¿qué pasa si tienes tu propia clase y quieres importar datos desde un archivo CSV a una tabla que ya existe previamente?
Hay varias formas de hacerlo, ¡pero puedes utilizar csvgen (o csvgen-ui) otra vez! Preparé un ejemplo y estoy encantado de compartirlo con todos. ¡Vamos allá!
El concepto es el siguiente: Tengo la clase A y quiero los datos del archivo.csv, ya que este archivo contiene una columna que necesito para mi clase.Los pasos son los siguientes:
Para explicar el concepto, creé una demostración sencilla del proyecto. El proyecto importa el conjunto de datos Countries, que contiene la clase dc_data.Country con información variada sobre los países, incluido el GNP (PIB en español).
ClassMethod ImportCSV() As %Status
{
set sc = ##class(community.csvgen).GenerateFromURL("https://raw.githubusercontent.com/evshvarov/test-ipad/master/gnp.csv",",","dc.data.GNP")
Return sc
}
Pero los datos del GNP están desactualizados y los más recientes se encuentran en este CSV. Este es el método que muestra el GNP, por ejemplo, para Angola:
ClassMethod ShowGNP() As %Status
{
Set sc = $$$OK
&sql(
SELECT TOP 1 name,gnp into :name,:gnp from dc_data.Country
)
if SQLCODE < 0 throw ##class(%Exception.SQL).CreateFromSQLCODE(SQLCODE,"Show Country GNP")
write "Country ",name," gnp=",gnp,!
Return sc
}
Entonces importo el CSV en una clase generada con una línea:
ClassMethod ImportCSV() As %Status
{
set sc = ##class(community.csvgen).GenerateFromURL("https://raw.githubusercontent.com/evshvarov/test-ipad/master/gnp.csv",",","dc.data.GNP")
Return sc
}
y con la segunda línea realizo una consulta en SQL que importa los datos actualizados del GNP a mi clase dc_data.Country.
ClassMethod UpdateGNP() As %Status
{
Set sc = $$$OK
&sql(
UPDATE dc_data.Country
SET Country.gnp=GNP."2020"
FROM
dc_data.Country Country
INNER JOIN dc_data.GNP GNP
On Country.name=GNP.CountryName
)
if SQLCODE < 0 throw ##class(%Exception.SQL).CreateFromSQLCODE(SQLCODE,"Importing data")
w "Changes to GNP are made from dc.data.GNP",!
Return sc
}
Y luego, elimino la clase generada (con todos sus datos) porque ya no la necesito.
ClassMethod DropGNP() As %Status
{
Set sc = $$$OK
&sql(
DROP TABLE dc_data.GNP
)
if SQLCODE < 0 throw ##class(%Exception.SQL).CreateFromSQLCODE(SQLCODE,"Drop csv table")
write "dc.data.DNP class is deleted.",!
Return sc
}
Y este es el método que hace todo al mismo tiempo:
ClassMethod RunAll() As %Status
{
Set sc = $$$OK
zw ..ImportDataset()
zw ..ShowGNP()
zw ..ImportCSV()
zw ..UpdateGNP()
zw ..ShowGNP()
zw ..DropGNP()
Return sc
}
Por supuesto, esta solo es una de las formas de solucionar el problema, pero espero que sea útil. ¡Me encantaría recibir vuestros comentarios!
En este artículo demostraré lo siguiente:
¡Hola Comunidad!
Hemos grabado el webinar que hicimos la semana pasada y lo hemos subido al canal de YouTube de la Comunidad de Desarrolladores en español. Si os perdisteis el webinar o lo queréis volver a ver con más detalle, ya está disponible la grabación!
Eduardo Anglada ha trabajado diez años en la Agencia Espacial Europea y nos descubrió muchas cosas interesantes sobre el espacio profundo. Así que... si queréis descubrir de forma práctica cómo crear modelos de Machine Learning, ¡no os perdáis el vídeo!
⏯ IntegratedML - Cómo crear modelos de Machine Learning en minutos
¡Hola desarrolladores!
Os invitamos a un nuevo webinar en español: "IntegratedML - Cómo crear modelos de Machine Learning en minutos", el jueves 30 de septiembre, a las 4:00 PM (CEST).

El webinar está dirigido a programadores que quieran empezar a crear modelos de Machine Learning (no hace falta ser un experto, con saber un mínimo de SQL es suficiente).
Este es un ejemplo de código que funciona en IRIS 2020.1 y en Caché 2018.1.3
No se mantendrá sincronizado con las nuevas versiones.
Y NO cuenta con el servicio de soporte de InterSystems.Este es un ejemplo de código que funciona en IRIS 2020.1 y en Caché 2018.1.3
No se mantendrá sincronizado con las nuevas versiones.
Y NO cuenta con el servicio de soporte de InterSystems.
En la mayoría de los casos, un global que se utiliza como almacenamiento predeterminado tiene solo 1 nivel de subíndice que representa el IDKEY.
Para un índice de globals podemos ver 2 o más niveles de subíndices.
Las matrices, las relaciones de herencia padre hijo o las clases persistentes que extienden una clase base, son ejemplos en los que vemos más niveles. Aunque todos estos globals son bastante uniformes.
Y después vemos globals que no están relacionados con clases o tablas como ^SPOOL, ^ERRORS, o ^%SYS, en los que la estructura depende de varios niveles de subíndices con un significado especial.
El análisis de esos globals no convencionales es un reto y el simple hecho de descargarlos no necesariamente ayuda a comprender las dependencias.
Este ejemplo está orientado al viejo chiste: "¿Cómo se come un elefante?" ==> "¡Cortándolo en porciones!"
Esa es la oferta:
Por medio de una sentencia SQL, se puede mostrar la estructura de cualquier global por niveles.
Tú proporcionas el nombre del global y el nivel máximo que mostrará, y obtienes los subíndices relacionados, $Data del nodo, la cantidad de los siguientes subnodos y, si está disponible, el contenido almacenado en ese nivel.
Por ejemplo: SELECT * FROM rcc_G.scan where rcc_G.Scan('^%SYS',1)=1
Reference Level $D SubN Value
^%SYS 0 10 25
("CSP") 1 10
("CSPAppSec") 1 1 64
("CacheTempDir") 1 1 "c:\intersystems\iris\mgr\iristemp\"
("DBRefByName") 1 10
("Ensemble") 1 11 "2020-04-25 18:37:18"
("ErrorPurge") 1 1 30
("FIPSMode") 1 1 0
("IRISTempDir") 1 1 "c:\intersystems\iris\mgr\iristemp\"
("JOURNAL") 1 11 0
("LANGUAGE") 1 10
("LASTSESSIONGUID") 1 1 "EÊcRù¢GM£ô"_$c(127)_"¹9¾ÒÆ"
("LOCALE") 1 10
("ModuleRoot") 1 10
("NLS") 1 10
("SERVICE") 1 10
("SSPort") 1 1 51773
("StreamLocation") 1 10
("SystemMode") 1 1 "TEST"
("TempDir") 1 1 "C:\InterSystems\IRIS\mgr\Temp"
("WebServer") 1 10
("bindir") 1 1 "c:\intersystems\iris\bin\"
("shutdownlogerrors") 1 1 0
("sql") 1 10
("sysdir") 1 1 "c:\intersystems\iris\mgr\"
("tercap") 1 10
26 lines
SELECT * FROM rcc_G.scan where rcc_G.Scan('^%SYS',2)=1
Reference Level $D SubN Value
^%SYS 0 10 25
("CSP") 1 10 1
("CSP","LastUpdate") 2 1 "65553,44452"
("CSPAppSec") 1 1 0 64
("CacheTempDir") 1 1 0 "c:\intersystems\iris\mgr\iristemp\"
("DBRefByName") 1 10 9
("DBRefByName","CACHE") 2 1 "^^c:\intersystems\iris\mgr\cache\"
("DBRefByName","CACHEUSER") 2 1 "^^c:\intersystems\user\"
("DBRefByName","ENSLIB") 2 1 "^^c:\intersystems\iris\mgr\enslib\"
("DBRefByName","IRISAUDIT") 2 1 "^^c:\intersystems\iris\mgr\irisaudit\"
("DBRefByName","IRISLIB") 2 1 "^^c:\intersystems\iris\mgr\irislib\"
("DBRefByName","IRISLOCALDATA") 2 1 "^^c:\intersystems\iris\mgr\irislocaldata\"
< 60 lines more >
SELECT * FROM rcc_G.scan where rcc_G.Scan('^ERRORS',37)=1 and id['Jour'
Reference Level $D SubNodes Value
(65588,1,"*STACK",1,"V","%00000","N","""JournalState""") 8 1 0 4
(65592,1,"*STACK",1,"V","%00000","N","""JournalState""") 8 1 0 4
(65592,2,"*STACK",1,"V","%00000","N","""JournalState""") 8 1 0 4