Tuve el mismo problema que contaba Jerry en el siguiente enlace al conectar IRIS con el servidor SQL. Mi conexión ODBC está configurada para autenticarse mediante autenticación nativa de Windows.
¿Cómo lo solucioné yo?
![]()
InterSystems Data Platform para soluciones en Open Exchange es una galería que cuenta con soluciones de software, herramientas y estructuras, las cuales se desarrollaron mediante la plataforma de datos de InterSystems (Caché, Ensemble, HealthShare, InterSystems IRIS, InterSystems IRIS for Health) o cuyo objetivo es ayudar con el desarrollo, implementación y compatibilidad de las soluciones construidas mediante InterSystems Data Platform.
Puede utilizar cualquiera de los activos publicados o publicar su propia herramienta, ejemplo tecnológico o solución.
Tuve el mismo problema que contaba Jerry en el siguiente enlace al conectar IRIS con el servidor SQL. Mi conexión ODBC está configurada para autenticarse mediante autenticación nativa de Windows.
¿Cómo lo solucioné yo?
Perfilando Documentos CCD con la Herramienta CCD Data Profiler de LEAD North
¿Alguna vez has abierto un CCD y te has encontrado con una pared de XML enredada? No estás solo. Aunque los CCD son un formato central para el intercambio de datos clínicos, son notoriamente densos, prolijos y poco amigables para la vista humana. Para los desarrolladores y analistas que intentan validar su estructura o extraer información significativa, navegar estos documentos puede sentirse más como arqueología que como ingeniería.
Uno de los desafíos al crear un mensaje DICOM es cómo poner los datos en el lugar correcto. Parte de ello es insertar los datos en las etiquetas específicas de DICOM, mientras que la otra parte es insertar datos binarios como una imagen. En este artículo explicaré ambos.
Para crear un mensaje DICOM, podéis usar la clase EnsLib.DICOM.File (para crear un archivo DICOM) o la clase EnsLib.DICOM.Document (para crear un mensaje que se pueda enviar directamente a PACS). En ambos casos, el método SetValueAt os permitirá añadir vuestros datos a las etiquetas DICOM.

En este artículo, discutiré el uso de un LLM alternativo para la IA generativa. OpenAI es comúnmente utilizado, pero en este artículo os mostraré cómo usarlo y las ventajas de utilizar Ollama.
En el modelo de uso de IA generativa al que estamos acostumbrados, seguimos el siguiente flujo:
Hola, Comunidad:
¡Más de 1000 aplicaciones ya están disponibles para que todos las descarguéis en InterSystems Open Exchange!
¡Y ahora es el momento de anunciar a los mejores desarrolladores y las aplicaciones más descargadas de 2024!
%20(2).jpg)
Echemos un vistazo más de cerca a nuestros héroes y sus aplicaciones:
Hola a todos,
Estoy buscando alguna herramienta que se pueda utilizar como base para crear una interfaz que permita a un usuario no técnico reenviar mensajes de manera sencilla. La idea es que el usuario pueda encontrar un mensaje HL7 ya enviado y reenviarlo modificando campos específicos del mensaje sin necesidad de tener ningún conocimiento técnico.
¿Preferís no leer? Echad un vistazo al vídeo demo:
En la última competición de InterSystems "Convirtiendo Ideas en Realidad", estuve explorando el portal de ideas en busca de problemas de interfaz de usuario para intentar resolverlos.
¡Manteneos al Día con las Notificaciones en Open Exchange!
Ahora podéis ver todas vuestras notificaciones directamente en el sitio web y elegir cómo queréis recibirlas: en la web, por correo electrónico o ambas opciones.
Esto es sobre lo que recibiréis notificaciones:
En este artículo, nos adentraremos en el funcionamiento de una aplicación publicada en OpenExchange llamada db-management-tool que sirve como herramienta de gestión de bases de datos, explorando la arquitectura y las tecnologías que la sustentan. Comprenderemos cómo funciona la aplicación para daros una visión de su diseño, cómo gestiona bases de datos, tablas y cómo la API interactúa con los datos.
Existen muchas aplicaciones para trabajar con mensajes HL7 V2, pero las herramientas para trabajar con XML en el Portal de Gestión o los IDE de IRIS son limitadas. Aunque hay muchas utilidades externas e IDEs que funcionan con mensajes XML e incluso documentos C-CDA, hay una razón convincente para poder hacer pruebas directamente en el marco de trabajo C-CDA de IRIS.
Hacer pruebas dentro del entorno de IRIS os proporciona el contexto necesario:
Dos grandes cambios para la herramienta de código abierto TestCoverage: Compatibilidad con Python integrado y una nueva interfaz de usuario.
Anteriormente, TestCoverage solo podía rastrear la cobertura de pruebas unitarias para el código escrito en ObjectScript. Ignoraba el código escrito en otros lenguajes como Python en las estadísticas de cobertura.

Hay un montón de grandes artículos de la comunidad con respecto a la «búsqueda de vectores en IRIS», y ejemplos en OpenExchange. Cada vez que los veo, ¡me encanta saber que tantos desarrolladores ya prueban los vectores en IRIS!
Pero si todavía no has probado los vectores en IRIS, dame un minuto y lo vemos 😄: creamos una clase IRIS y con eso ya es suficiente para ver cómo pones datos vectoriales en tu base de datos IRIS y cómo los comparas en tu aplicación.
Hola Comunidad,
En este artículo, voy a presentar mi aplicación iris-RAG-Gen .
Iris-RAG-Gen es una aplicación generativa AI Retrieval-Augmented Generation (RAG) que aprovecha la funcionalidad de IRIS Vector Search para personalizar ChatGPT con la ayuda del framework web Streamlit, LangChain, y OpenAI. La aplicación utiliza IRIS como almacén de vectores.
IrisFirebase - FCM

Una solución de control de versiones eficaz permite a las organizaciones gestionar bases de código complejas, facilitar una colaboración sin fisuras dentro de los equipos de desarrollo y agilizar los procesos de despliegue.
Hola Comunidad,
En este artículo, os demostraré los siguientes pasos para crear vuestro propio chatbot utilizando spaCy (spaCy es una biblioteca de software de código abierto para el procesamiento avanzado del lenguaje natural, escrita en los lenguajes de programación Python y Cython):
Empecemos
Hola Comunidad,
Nos complace invitaros al próximo concurso de programación online de InterSystems, ¡centrado en Python!
🏆 Concurso InterSystems Python 🏆
Duración: 15 julio - 4 agosto, 2024
Bolsa de premios: $14,000
.jpg)
Esta es una guía de instrucciones paso a paso para crear una tarea que recopile datos sobre la base de datos InterSystems y los globales que contiene (como se ve en la Open Exchange App asociada - encontrad todo el código asociado allí).
Descargo de responsabilidad: Este software es meramente para fines de PRUEBA/DEMO. Este código no está soportado por InterSystems como parte de ningún producto. InterSystems lo suministra como herramienta de demostración/prueba para un producto y versión específicos. El usuario o cliente es totalmente responsable del mantenimiento y prueba de este software después de la entrega, e InterSystems no tendrá ninguna responsabilidad por errores o mal uso de este código.
En primer lugar, importad el archivo «DataCollection.xml» a través del portal de gestión y aseguraos de que no hay errores. Si los hubiera, podría tratarse de una cuestión de versiones. Poneos en contacto con Ari Glikman en ari.glikman@intersystems.com para que os ayude a obtener una versión adecuada para vosotros. Además, aseguraos de que importáis los datos en el espacio de nombres cuyos datos internos queréis recopilar para su posterior inspección.
Una vez finalizada la importación, deberíais ver el paquete Sample/Muestra con varios subpaquetes también
Si un paquete de Sample/Muestra ya está presente en vuestro servidor, entonces todavía debéis ver los nuevos subpaquetes junto con cualquier otra carpeta que estaban previamente allí.
a. Cread una carpeta llamada Unit Tests que pueda ser leída por vuestro Terminal InterSystems, por ejemplo, como yo tengo una instalación local, haré una carpeta en mi disco C.
b. En esta carpeta exportaremos ahora la clase Sample.DBExpansion.Test.CaptureTest como un fichero xml.
c. En el terminal estableced el global ^UnitTestRoot = “<< carpeta en la que está Unit Tests>>”.. Según el ejemplo anterior, sería (tened en cuenta que debe estar en el mismo espacio de nombres donde importasteis el paquete) C:\ (a tener en cuenta que no es “C:\Unit Tests” !)
set ^UnitTestRoot = "C:\"
d. Por último, ejecutamos las pruebas unitarias. Hacedlo ejecutando la siguiente línea de código desde el terminal:
do ##class(Sample.DBExpansion.Test.TestManager).RunTest("Unit Tests", "/noload/nodelete")
Esencialmente le estamos diciendo al programa que ejecute todas las pruebas que se encuentran en la carpeta C:\Unit Tests. Por el momento sólo tenemos un archivo allí, el creado en 3.b.
La salida debería ser la siguiente
Si las pruebas unitarias no pasan, entonces el programa no está listo para ejecutarse. No continuéis con los siguientes pasos hasta que obtengáis una salida que diga que todas las pruebas han pasado.
a. Abrid el portal de gestión e id a Operación del Sistema > Gestor de Tareas > Nueva Tarea
*Tened en cuenta que vuestro usuario debe tener acceso al espacio de nombres %SYS, de lo contrario la tarea se ejecutará pero no recopilará ningún dato.
Ahora se os darán varios campos para rellenar en cuanto a la tarea que queréis crear. Deberéis elegir el espacio de nombres en el que importasteis el paquete y dar un nombre a la tarea. Deberéis dar una descripción para futuras referencias. Lo ideal es dejar la casilla de verificación rápida sin marcar, esto significa que la tarea se ejecutará más lentamente pero recogerá datos más completos. Si tarda demasiado en ejecutarse (depende de lo grande que sea la base de datos y sus globales) entonces quizás sea mejor marcar aquí y optar por una tarea más rápida. HowManyGlobals indica cuántos datos globales deben recopilarse: -1 indica todos los datos globales y es la opción recomendada. Seleccionad Siguiente, elegid con qué frecuencia debe ejecutarse la tarea y pulsad Finalizar.
b. Aparecerá el Calendario de Tareas, donde podréis ver cuándo están programadas todas las tareas, incluida la recién creada. Si además deseáis ejecutarla ahora, seleccionad Ejecutar en la parte derecha.
Seleccionad el Historial de Tareas para asegurar que se ha creado correctamente. Después de ejecutar la tarea deberíais ver que también se ha ejecutado correctamente. En caso contrario, aparecerá un error.
Esta tarea creará dos tablas:
Sample_DBExpansion_Data.DBAnalysisInfo.
Esta tabla va a almacenar datos sobre la propia base de datos. Nos referimos a esto como «metadatos». La información que almacena se puede ver en la siguiente imagen. La Bandera Rápida indicará la selección elegida en 4.a.
Sample_DBExpansion_Data.GlobalAnalysisInfo
Esto contendrá la información relativa a los globales en la base de datos. Observad que si hay un nombre de clase asociado al global, lo veremos aquí junto con su tamaño. Por último, observad que el campo MetaDataID corresponde al campo ID de la tabla Sample_DBExpansion_Data.DBAnalysisInfo. Esto quiere decir que en el momento en que se capturó la información de la base de datos, se capturó su correspondiente información global y comparten este número identificativo (son los globales de la base de datos en ese momento). Es una forma de ver cómo evolucionan en el tiempo los globales de una base de datos y la propia base de datos.
Muestra información sobre el global y la base de datos que aparecen en la tabla de una manera más digerible. Hay 3 gráficos: uno que muestra la historia de los datos, el segundo que muestra los tamaños históricos de un global elegido, ya sea a través del desplegable o de una búsqueda, y por último hay una visión general de todos los tamaños globales. En la parte inferior hay una tabla donde se introduce cuántos globales se quieren mostrar y los presenta ordenados por tamaño. La columna %Change está resaltada en amarillo para un cambio mínimo de tamaño, en verde para una disminución de tamaño y en rojo para un aumento significativo de tamaño.
Encontraréis instrucciones paso a paso sobre cómo configurarlo aquí.
Si no os interesan los gráficos, continuad con el análisis de datos aquí.
Aseguraos de tener git y Docker desktop instalados.
Clone/git pull el repo en cualquier directorio local
$ git clone https://github.com/rcemper/PR_DataCollection.git
$ docker compose up -d && docker compose logs -f
Inicio del contenedor
cread el directorio apropiado «/home/irisowner/dev/Unit Tests»
estableced ^UnitTestRoot = «/home/irisowner/dev/»
Para abrir el Terminal IRIS:
$ docker-compose exec iris iris session iris
USER>
o utilizando WebTerminal.
http://localhost:42773/terminal/
Para acceder al portal de gestión del sistema IRIS
http://localhost:42773/csp/sys/UtilHome.csp
Para acceder a UnitTestPortal http://localhost:42773/csp/sys/%25UnitTest.Portal.Indices.cls?$NAMESPACE=USUARIO
¡Hola Comunidad!
En mi artículo anterior, aprendimos estos temas:
En este artículo trataré los siguientes temas:
Comencemos.
La Inteligencia Artificial (IA) está recibiendo mucha atención últimamente porque puede cambiar muchos aspectos de nuestras vidas. Una mayor potencia informática y más datos han ayudado a la IA a hacer cosas asombrosas, como mejorar las pruebas médicas y fabricar coches que se conducen solos. La IA también puede ayudar a las empresas a tomar mejores decisiones y a trabajar de forma más eficiente, por lo que cada vez es más popular y se utiliza más. ¿Cómo se pueden integrar las llamadas a la API OpenAI en una aplicación de interoperabilidad IRIS existente?

En este artículo, compartiré el tema que presentamos @Rochael Ribeiro y yo en la Convención Anual (Global Summit) 2023, en la sala "Tech Exchange".
En esa ocasión hablamos de los siguientes temas:
Como estamos hablando de desarrollo rápido de APIs modernas (Rest / json) utilizaremos dos herramientas de Open Exchange:
La primera es un framework para el desarrollo rápido de APIs, que explicaremos en este artículo.
https://openexchange.intersystems.com/package/IRIS-apiPub
La segunda es utilizar Swagger como interfaz de usuario para la especificación y documentación de las APIs Rest desarrolladas en la plataforma IRIS, así como su uso/ejecución. La base de su funcionamiento es la especificación OpenAPI (OAS) estándar, que se describe a continuación:
https://openexchange.intersystems.com/package/iris-web-swagger-ui

Es un estándar utilizado en todo el mundo para definir, documentar y consumir APIs. En la mayoría de los casos, las APIs se diseñan incluso antes de su implementación. Hablaré más de ello en los próximos apartados.
Es importante porque define y documenta las APIs Rest para su uso, tanto en el lado del proveedor como del consumidor. Pero este patrón también sirve para agilizar las pruebas y las llamadas a las API en las herramientas (Clientes de las APIs Rest) del mercado, como Swagger, Postman, Insomnia, etc…

Imaginemos que tenemos que crear y publicar una API Rest a partir de un método IRIS existente (imagen inferior).
De la forma tradicional:
1: Tenemos que pensar cómo la llamarán los consumidores. Por ejemplo: Qué ruta y verbo se utilizará y cómo será la respuesta. Ya sea en un objeto JSON o como texto plano.
2: Crear un nuevo método en una clase %CSP.REST que administrará la solicitud http para llamarlo.
3: Gestionar la respuesta del método a la respuesta http prevista para el usuario final.
4: Pensar cómo vamos a proporcionar el código de respuesta y cómo vamos a gestionar las excepciones.
5: Mapear la ruta para nuestro nuevo método.
6: Proporcionar la documentación de la API al usuario final. Probablemente crearemos el contenido OAS manualmente.
7: Y si, por ejemplo, tenemos una carga útil (objeto) de solicitud o respuesta, el tiempo de implementación aumentará, porque también debe documentarse en OAS.

Simplemente etiquetando el método IRIS con el atributo [WebMethod]. Sea lo que sea, el framework se encargará de su publicación, utilizando el estándar OAS 3.x.

Porque también documenta detalladamente todas las propiedades de las cargas útiles de entrada y salida.
De esta forma, cualquier herramienta Rest Client del mercado puede acoplarse instantáneamente a las API, como Insomnia, Postman, Swagger, etc. y ofrecer un contenido de muestra para llamarlas fácilmente.
 Usando Swagger ya visualizaremos nuestra API (imagen superior) y la llamaremos. Esto también es muy útil para realizar pruebas.
Usando Swagger ya visualizaremos nuestra API (imagen superior) y la llamaremos. Esto también es muy útil para realizar pruebas.
Pero, ¿y si necesito personalizar mi API?
Por ejemplo: En vez del nombre del método, quiero que la ruta sea otra cosa. Y quiero que los parámetros de entrada estén en la ruta, no como un parámetro de consulta.
Definimos una notación específica en la parte superior del método, donde podemos complementar la metainformación que el propio método no proporciona.
 En este ejemplo estamos definiendo otra ruta para nuestra API y complementando la información para que el usuario final tenga una experiencia más amigable.
En este ejemplo estamos definiendo otra ruta para nuestra API y complementando la información para que el usuario final tenga una experiencia más amigable.
Este framework soporta numerosos tipos de parámetros.
En este mapa podemos destacar los tipos complejos (los objetos). Se expondrán automáticamente como una carga útil JSON y cada propiedad estará debidamente documentada (OAS) para el usuario final .

Al admitir tipos complejos, también se pueden exponer servicios de interoperabilidad.
Es un escenario favorable para crear APIs compuestas, que utilizan la orquestación de múltiples componentes externos (salidas).

Esto significa que los objetos o mensajes utilizados como solicitud o respuesta serán publicados y leídos automáticamente por herramientas como swagger.
Y es una forma excelente de probar componentes de interoperabilidad, porque normalmente ya se sube una plantilla de carga útil para que el usuario sepa qué propiedades utiliza la API.
En primer lugar, el desarrollador puede centrarse en las pruebas y, a continuación, dar forma a la API mediante la personalización.

Otro concepto muy utilizado hoy en día es tener la API definida incluso antes de su implementación.
Con este framework es posible importar una especificación OpenAPI. Crea la estructura de los métodos (especificación) automáticamente, y faltaría sólo su implementación.

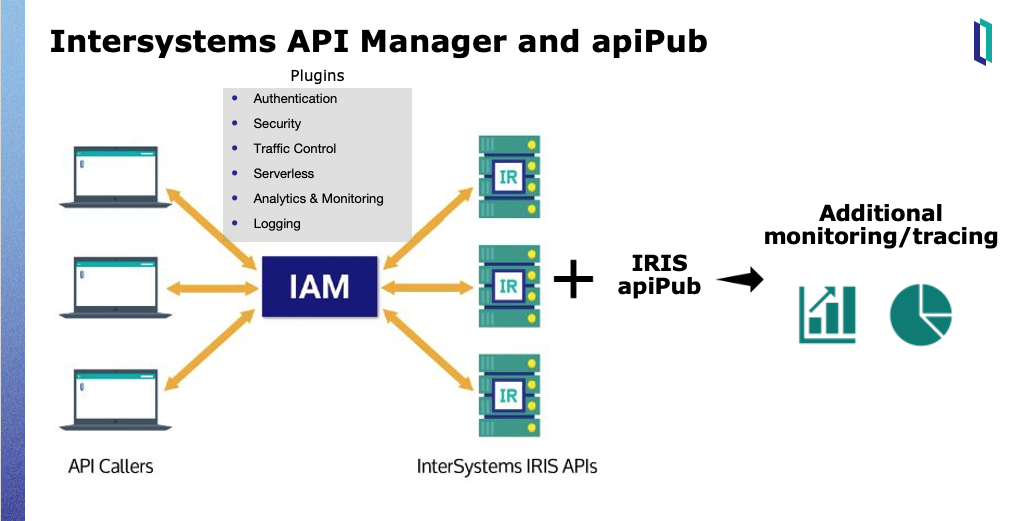
Para la gobernanza de las APIs, también se recomienda utilizar conjuntamente IAM.
Además de disponer de múltiples plugins, IAM puede acoplarse rápidamente a las APIs a través del estándar OAS.
apiPub ofrece trazabilidad adicional para las APIs (ver el video demostración)
<iframe allowfullscreen="" frameborder="0" height="432" scrolling="no" src="https://www.youtube.com/embed/IdJ1PqmhH3c" width="768"></iframe>
Intersystems Open Exchange: https://openexchange.intersystems.com/?search=apiPub
Documentación completa: https://github.com/devecchijr/apiPub
Como seguramente ya sabréis la mayoría de vosotros, desde aproximadamente finales de 2022 InterSystems IRIS incluyo la funcionalidad de almacenamiento columnar a su base de datos, pues bien, en el artículo de hoy vamos a ponerla a prueba en comparación con el almacenamiento en filas habitual.
¿Cuál es la principal característica de este tipo de almacenamiento? Pues bien, si consultamos la documentación oficial veremos esta fantástica tabla que nos explica las principales características de ambos tipos de almacenamiento (por filas o por columnas):

Hola, comunidad!
He estado trasteando últimamente con Flutter y he desarrollado algunas aplicaciones que usan Firebase como base de datos. Cuando descubría que existía una librería de Firebase para Python, tuve el impulso de que debía crear algo con InterSystems IRIS que pudiese hacer que se comunicase con Firebase Database RealTime y realizar operaciones CRUD. Justo entonces me encontré con esta idea de Evgeny en el portal de ideas:
https://ideas.intersystems.com/ideas/DP-I-146
Y me puse manos a la obra!
¡Hola Comunidad!
Ya hay más de 800 aplicaciones disponibles para descargar enOpen Exchange.
Y ha llegado el momento de anunciar las apps más descargadas y los mejores desarrolladores de 2023!
.jpg)
Estos son los héroes y sus apps:

La inteligencia artificial no se limita solo a generar imágenes a través de texto con instrucciones o crear narrativas con instrucciones sencillas.
También puedes hacer variaciones de una imagen o incluir un fondo especial a una ya existente.
Adicionalmente, podrás obtener la transcripción del audio sin importar su idioma y la velocidad del hablante.
Por tanto, analicemos cómo funciona la gestión de archivos.

En un entorno clínico acelerado, en el que la toma rápida de decisiones es crucial, la falta de sistemas eficientes de almacenamiento y acceso a los documentos plantea varios obstáculos. Aunque existen soluciones de almacenamiento de documentos (por ejemplo, FHIR), el acceso y la búsqueda eficaz de datos específicos de pacientes dentro de esos documentos puede suponer todo un reto.
La IA ha hecho que la búsqueda de documentos sea extraordinariamente potente. Preguntar y responder sobre documentos nunca ha sido tan fácil con herramientas de código abierto como Chroma y Langchain para almacenar y utilizar incrustación de palabras (vector embeddings) para consultas a las APIs de IA generativa. Con un esfuerzo más dedicado, las organizaciones están indexando sus documentos existentes y construyendo versiones ajustadas de GPT con fines empresariales. La charla de Andrej Karpathy sobre el estado de GPT ofrece un excelente resumen general sobre este tema.
Este proyecto fue nuestro intento de reducir la fricción en todos los puntos de contacto en los que el personal médico tiene que interactuar con documentos. Desde la entrada y la gestión hasta el almacenamiento y la recuperación, hemos aprovechado IRIS FHIR y la IA para ayudarles a almacenar y encontrar la información que necesitan sin esfuerzo.
Hemos creado una aplicación web full-stack que permite a los médicos grabar notas de voz. A continuación, estas notas pueden transcribirse y resumirse mediante Open AI y almacenarse en servidores FHIR. Después, los documentos almacenados se indexan y están disponibles para la búsqueda semántica.
Clonad el repositorio del proyecto desde este enlace de GitHub: https://github.com/ikram-shah/iris-fhir-transcribe-summarize-export. Seguid las instrucciones proporcionadas para configurar el proyecto localmente en vuestros equipos. Y hacednos saber si algo no funciona como se esperaba.
Los avanzados modelos de lenguaje disponibles actualmente, combinados con el enorme volumen de datos disponibles, encierran un inmenso potencial para revolucionar la atención sanitaria, especialmente en lo relativo a los documentos.
Dejadnos vuestros comentarios a continuación. Publicaremos más artículos con los detalles técnicos de este proyecto.
¡Hola desarrolladores!
Os invitamos a un nuevo concurso de programación de InterSystems, en esta ocasión centrado en Java y sus derivados.
🏆 Concurso de Programación: Java 🏆
Duración: del 13 de noviembre al 3 de diciembre, 2023
Total en premios: $14,000
.jpg)